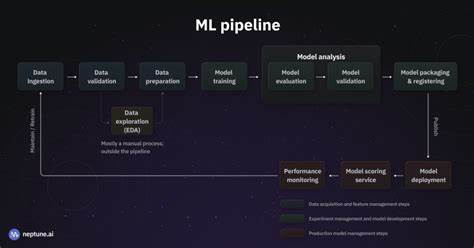
随着人工智能和机器学习技术的快速发展,构建一个高效且可复用的机器学习流水线框架成为众多开发者和数据科学家的迫切需求。机器学习流水线不仅能够帮助团队规范数据预处理、特征工程、模型训练和部署流程,还能极大提高项目的自动化水平和协作效率。近期,有开发者分享了他构建的开源机器学习流水线自动化框架——MLFCrafter,并诚恳地寻求社区的反馈与改进建议,这为我们理解和完善机器学习流水线提供了宝贵的参考。机器学习流水线的核心在于模块化与自动化,MLFCrafter正是基于这一理念设计,将不同的组件如数据清洗模块(CleanerCrafter)、数据标准化模块(ScalerCrafter)以及模型训练模块(ModelCrafter)通过一个核心链路(MLFChain)连接起来,鼓励用户构建灵活且可复用的流水线结构。这种设计避免了重复代码,降低了工作复杂性,为项目开发者节省大量时间。同时,开放源代码为社区贡献者提供了参与和改进的机会,有助于框架的持续迭代和优化。
尽管如此,开发者也意识到推广新框架面临诸多挑战。机器学习领域变化迅速,众多企业和团队已有成熟工具和平台,用户对新框架的接受度较低,特别是在项目压力和紧迫交付的背景下,更倾向于依赖稳定且广泛支持的工具。对此,社区反馈建议开发者不必从零开始构建完整流水线框架,而是应考虑在现有主流平台之上进行增值和扩展,比如在Metaflow生态系统中打造自动化层。这种做法能够借助已有用户群体和生态资源,降低用户引入门槛和迁移成本,同时提升框架的实际市场适配度和竞争力。具体而言,改进一个机器学习流水线框架时,首先需要重视文档和示例的设计。完善且易于理解的文档是吸引用户尝试和应用的基石。
不少潜在用户在第一时间阅读项目说明时,如果文档链接失效或缺少清晰的示例代码,很容易流失。项目主页和README应能直观展示完整流水线代码样例,突出框架的独特优势和核心价值,快速帮助用户了解主要功能和使用方式。同时,名称和命名风格也影响用户体验。例如,组件名中频繁出现类似“Crafter”的后缀,有可能带来阅读和记忆负担,简洁且一致的命名风格更有利于传递清晰信息。用户体验方面,框架应尽可能简化初始化和配置步骤,减少繁琐的设置行数,提升使用便利性。此外,支持用户一次性向整个流水线传递输入数据,并借助Python上下文管理(如with语句)实现流水线的自动管理和上下文切换,能够大幅提升代码优雅度和易用性。
除了框架本身技术层面的改进,开源项目的推广策略也至关重要。从个人开发者独立维护到构建稳定活跃的社区,关键在于提供持续的价值,积极回应用户反馈,以及通过多渠道传播提升项目知名度。进行代码质量保证、保持频繁更新、举办线上线下分享或工作坊均能助力项目快速成长。借助GitHub、技术论坛、社交媒体和专业会议,建立合作伙伴关系和用户群体,为项目注入活力。选择适合的技术栈和集成平台,考虑商业用户的需求和反馈,有针对性地扩展功能模块和集成工具,也是提升框架生命力的重要环节。总之,构建优秀的机器学习流水线自动化框架绝非一朝一夕之功,需要开发者在技术设计、用户体验、社区建设和生态融合上多方面发力。
从模块化设计理念出发,结合自动化、标准化的思想,汲取社区反馈加以改进,稳健推进开源项目的发展。未来在强大的生态平台支撑和用户认可下,自动化流水线框架必将成为机器学习项目效能提升的重要助推器,助力企业和开发者实现智能化转型升级。









