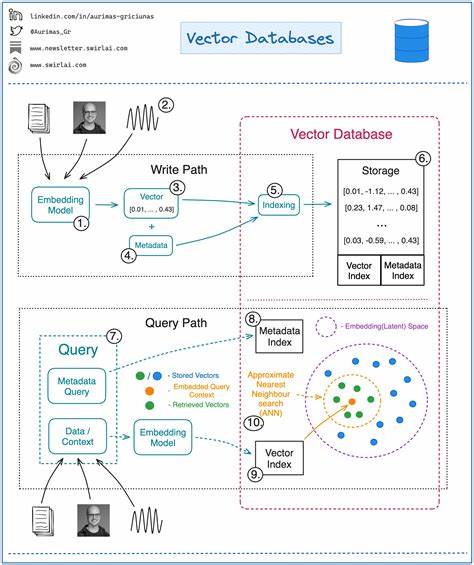
在当今大数据和人工智能蓬勃发展的时代,数据不仅数量庞大,而且形式日益多样复杂。传统的关系型数据库虽然稳定可靠,但面对图片、音频、视频、社交媒体文本等非结构化数据时,却显得力不从心。大量无法归纳进固定表格结构中的信息,使得数据的存储与检索变得困难。而向量数据库应运而生,成为处理这类复杂数据的关键利器。它们不仅能精准表达数据内涵,还能高效实现相似性搜索,推动智能应用的飞速发展。向量数据库因此被业界誉为人工智能时代的数据库新纪元。
日常生活中的许多智能体验,背后都离不开向量数据库的支持。 非结构化数据的海量存在给传统数据库带来了巨大挑战。当前,约80%的数据属于非结构化状态,包括图片、音频、视频、邮件以及文本文件等。这类数据本质上缺乏明确的列与行的组织形式。举例来说,一张图片的像素值虽然详细,却难以直接通过传统数据库实现内容相似的搜索。我们常见的方法是给图片手动添加标签或关键词,但这种做法耗时且主观性强,难以应对大规模数据的需求。
此外,文本内容中微妙的语义差异和上下文联系,也很难完全通过关键词匹配捕捉。 向量数据库的核心优势在于其通过向量的形式将复杂数据转化为计算机能够理解和比较的数字表达。简单来说,向量是由多个数字组成的数组,可以看作是数据在多维空间中的坐标。利用机器学习及深度学习模型,可以将文字、图片、音频等转化为高维向量,即在一个高维空间中以点的形式表示其独特特征和内在语义。这种方法允许系统通过数学距离和角度来衡量不同数据的相似度,超越了传统关键词的限制。 例如以颜色为例,颜色可以用三维向量表示,分别代表红色、绿色和蓝色的强度。
红色可表示为[1.0, 0.0, 0.0],绿色是[0.0, 1.0, 0.0],蓝色为[0.0, 0.0, 1.0]。紫色混合了红与蓝,对应向量大致为[0.5, 0.0, 0.5]。通过计算不同颜色向量的相似度,可以量化紫色和红色的接近度,进而实现基于颜色的精准搜索。文本数据的转化则更为复杂,需应用自然语言处理中的词嵌入技术,将单词或句子转成数百甚至上千维的向量,捕捉语义关系。例如“轿车”和“SUV”这两个词,在向量空间中彼此距离较近,反映了它们在实际语境中的相关性。 在向量数据库中衡量向量之间相似性的常用方法是余弦相似度和欧氏距离。
余弦相似度关注两个向量之间夹角的大小,当向量方向完全一致时,相似度为1.0,反之为-1.0。通过计算余弦相似度,可以比较不同数据的语义相关性。比方说,向量[1,2,3]和[2,4,6]的余弦相似度为1,表明它们指向相同的方向,具高相似性。欧氏距离则是多维空间中两点间的直线距离。距离越小,表示向量越接近,所表示的数据对象越相似。这些数学工具使得遍历大规模向量数据集时,能够快速识别出与查询向量最接近的内容。
然而,面对数百万乃至数十亿规模的向量数据,如何快速检索变得至关重要。顺序遍历每一个向量显然效率极低。为此,向量数据库采用了专门设计的索引技术来优化检索速度。类似于传统数据库中的B树或哈希表索引,向量数据库利用近似最近邻算法(ANN)、分层可导航小世界图(HNSW)以及产品量化等复杂算法结构,将向量数据组织成高效的索引结构。通过该结构,系统可以在庞大数据集中迅速锁定与查询向量最相近的候选项,大幅提升查询响应速度,同时保持较高的准确率。 这些技术的应用极大扩展了智能系统的场景和能力。
例如现代搜索引擎不仅依赖关键词匹配,而是将用户查询转为向量形式,再与网页内容向量相匹配,实现语义层面的理解。因此,即便查询和结果之间表述不同,也能精准捕捉到用户真实需求,提升搜索相关性和用户满意度。在社交媒体和图像平台上,向量数据库帮助实现基于内容的图像检索、重复内容检测以及智能推荐。例如Instagram可将图片转化为描述颜色、形状及艺术风格的向量,从而推荐视觉风格相似的图片或标记违规内容。视频平台亦利用向量表示分析场景和关键帧,支持自动生成推荐列表和亮点剪辑。 总的来说,向量数据库作为连接海量非结构化数据与智能应用的桥梁,正在引发数据库技术与应用模式的革命。
它通过数学与机器学习的深度结合,不仅解决了传统数据库难以处理的结构化问题,也推动了搜索、推荐和内容理解等多个领域的创新发展。对于希望构建精确、高效智能系统的开发者和企业来说,理解并掌握向量数据库技术无疑将成为未来制胜的关键。随着技术不断进步和应用场景丰富,向量数据库必将迎来更加广阔的发展前景,助力数字化时代的智能变革不断迈向新高度。