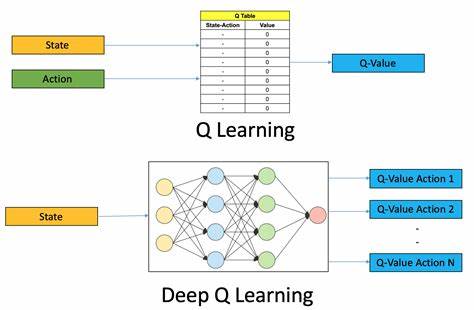
随着人工智能技术的飞速发展,强化学习作为机器学习的重要分支,正在不断推动游戏智能和自主决策能力的革新。尤其是Q学习结合神经网络的算法,因其在复杂环境中适应性强和学习效率高的优势,备受研究者和开发者的青睐。本文将深入探讨Q学习算法的核心原理,分析神经网络如何赋能传统Q学习,使其能够在经典第一人称射击游戏Quake中实现卓越的智能行为表现。强化学习的本质是让智能体通过与环境的交互,不断优化其决策策略,以实现某种预期的长期目标。Q学习作为一种无模型的强化学习方法,通过更新状态-动作值函数,指导智能体选择最优动作。传统Q学习在状态空间有限且离散的环境中表现稳定,但面对Quake这类高维度、连续状态空间的复杂游戏时,单纯使用表格型Q函数存储显得捉襟见肘。
神经网络的引入极大地改变了这一局面。通过将神经网络作为Q函数的近似器,智能体得以在庞大的状态空间中进行有效泛化,捕捉环境的非线性特征和复杂结构,提升了学习的速度与质量。这种结合也被称为深度Q网络(Deep Q-Network,DQN)技术。Quake作为一款标志性的第一人称射击游戏,以其复杂的地图设计、多样化的武器系统和实时交互机制,成为测试强化学习算法的理想平台。智能体在Quake中不仅需要快速反应敌人动作,还要合理利用地形优势和资源,制定长远战略。由神经网络驱动的Q学习智能体正是通过对大量游戏数据和反馈的反复学习,不断微调其策略,实现了从初学者到顶级玩家的飞跃表现。
在实际应用过程中,Q学习智能体采用卷积神经网络(CNN)处理来自Quake的视觉信息,将画面像素转化为高维特征表示。这些特征被输入到深层网络中,预测在当前状态下每个可能动作的期望回报。智能体根据最大Q值选择行动,持续通过奖励信号强化有效行为。该过程需要大量的训练时间和计算资源,但最终能够自主发现游戏中的有效战术和躲避策略。例如,智能体学会利用地图中的狭窄通道设伏、智能切换武器应对不同敌人,甚至预测对手行为,从多方面提升了竞技表现。此外,Q学习与神经网络的结合在Quake中的成功应用,不仅为游戏AI注入了新的生命力,也促进了自主学习系统在现实世界问题上的探索。
自动驾驶、机器人导航、金融投资等领域均可借鉴这种方法,实现复杂环境下的智能决策和自主适应。面对未来,虽然深度Q学习技术已取得显著成就,但挑战依然存在,比如训练过程中的样本效率、探索与利用的平衡以及模型稳定性等问题。研究者们正不断通过改进算法结构、引入迁移学习、多智能体协作机制等手段,克服这些瓶颈,推动人工智能应用迈向更高台阶。总结来看,Q学习与神经网络的结合,是强化学习领域的重要突破。Quake这款经典游戏成为该技术验证与演进的绝佳战场,展现了智能体自主学习与决策的无限潜力。毫无疑问,随着算法和硬件的不断进步,神经网络驱动的强化学习将在更多复杂任务中大展拳脚,引领人工智能进入一个崭新的智能时代。
。