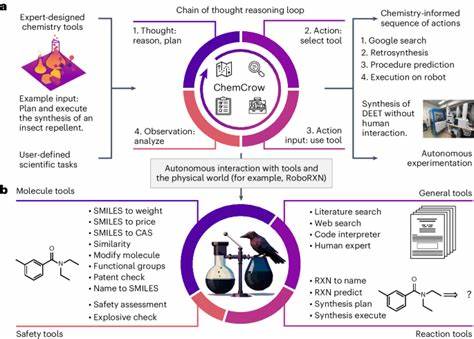
近年来,大型语言模型(Large Language Models,简称LLMs)因其强大的语言理解与生成能力,在多个专业领域引发广泛关注。化学作为一门高度依赖复杂知识和严密逻辑推理的学科,也逐渐成为人工智能应用的重点方向。特别是随着ChemBench等专业评测框架的建立,人们开始更加系统和客观地评估大型语言模型在化学领域的表现,探索其是否具备媲美甚至超越人类专家的能力。大型语言模型通过海量文本数据进行训练,能够在未经过专门设计的任务中灵活应对,甚至表现出惊人的推理与判断能力。针对化学学科,这意味着模型不仅可以回答基础化学知识,也能解决涉及计算、分析和化学直觉的复杂问题。最新研究显示,部分顶尖模型在ChemBench测试中整体表现优于普通化学专业人士,这一发现震惊了学术界并引发对未来化学科研和教学的深刻思考。
然而,深入分析表明,尽管大型语言模型在很多任务中表现优秀,但它们仍然存在明显短板,尤其是在需要精确化学结构推理和安全性判断的领域。模型通常更依赖于训练数据的相似度匹配,而非真正的深度化学理解。这种“记忆型”表现使得它们在面对新颖或复杂问题时,会产生过于自信却错误的回答,对于涉及化学安全和毒性的判断更是不可靠。此外,模型在判断化学家偏好或评价化学设计任务中仍无法体现人类专家的直觉和经验,表现基本处于随机水平。用户如果盲目信任这些结果,可能导致严重后果。大型语言模型的规模和训练数据量普遍与其性能正相关,这意味着未来模型随着硬件与算法的进步有望持续提升。
然而,单纯扩大规模无法根本解决所有问题。针对化学知识的深入整合以及与专业数据库的结合,将成为提升模型表现的关键路径。当前主流模型虽然对文本和部分分子描述有一定处理能力,但缺乏对分子立体结构和动态性质的精准表达能力,限制了其在某些细分领域的应用范围。评测体系的设计同样影响着对模型表现的认识。传统的考试题和多选题不完全能反映现实科学研究的复杂性和多样性。ChemBench通过涵盖多样主题、技能需求和难度层次的问题,提供更全面的能力画像,揭示了模型与人类专家在不同领域的优劣势。
值得注意的是,在某些标准化考试题中,模型能够轻松超越人类,但在需要多步推理或跨知识融合的情境下,则表现逊色。这一现象启示教育者应重新审视化学教学方法,强化批判性思维和综合推理能力培养,避免单纯记忆与题海战术。另一个亟需关注的方面是模型的置信度估计能力。研究表明,模型自我评估正确率的能力普遍较弱,在错误回答时往往表现出较高的信心,这对科研工作者和学生的使用安全构成隐患。未来研究需要开发更健壮的置信度校准方法,确保模型输出的可靠性和透明度。大型语言模型在化学领域的崛起,也引发了伦理和安全方面的担忧。
其技术既可用于发现新药、设计环保材料,也同样可能被恶意利用于合成有害化学品或武器。因此,建立有效的监管机制和模型使用规范是保障社会安全的重要一环。同时,科学界需推动跨学科合作,整合化学专业知识与人工智能技术,打造更智能、更可信赖的辅助工具,助力科研效率提升。未来,集成多模态信息(如分子三维结构图、光谱数据)与语言理解能力的复合型模型,将成为突破所在。它们能够更真实地模拟化学家在实验设计、数据解析中的思考过程,提供创新性建议,推动自动化实验和智能化材料发现。此外,拓展模型对化学领域偏好的学习能力,将优化早期药物筛选和分子设计中的决策效果。
总之,当前大型语言模型在化学知识和推理方面已展现出强大潜力,甚至在某些任务中超越人类专家。然而,它们仍然受到数据覆盖、推理深度、安全性保障等多方面限制。通过持续改进训练方法、集成专门数据库和增强多模态能力,可以期待模型在未来更好地支持化学研究。与此同时,教育体系需改革以适应智能辅助时代,培养具备深层次理解和批判性思维的化学人才,确保人工智能成为科学探索的有力助手而非不可控风险。随着ChemBench等评测平台不断完善,社区合作持续深化,我们有望迎来一个人机协同、提升科学创新速度的崭新化学科研时代。