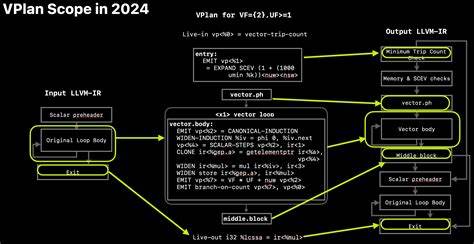
在现代编译器优化领域,自动矢量化作为提升程序执行效率和充分利用硬件矢量处理单元(VPU)的重要手段备受关注。LLVM作为领先的开源编译基础设施,其循环矢量化器(loop vectorizer)具备强大的自动矢量化能力。而在这一机制背后,矢量化规划器(Vectorization-Planner,简称VPlan)扮演了至关重要的角色。通过引入一个抽象层级并插件式地管理矢量化策略,VPlan不仅提升了矢量化的灵活性和可扩展性,还极大地优化了代码生成质量。本文将系统解读LLVM中VPlan的设计架构、工作原理以及具体实现细节,助您深入理解其运作机制及实际应用价值。 LLVM的矢量化器与传统的编译器优化不同,它并非直接操作底层的LLVM中间表示(IR),而是将IR提升为一种覆盖层IR,这就是VPlan所使用的抽象表示。
该抽象覆盖层既保留了原有IR的语义信息,也植入了矢量化相关的策略和信息,方便针对不同矢量化因子(vectorization factor, VF)和展开因子(unroll factor, UF)进行灵活规划与变换。 以一个典型的矢量化示例 - - saxpy函数为例,函数对数组逐元素执行标量运算。LLVM编译器首先对该函数进行一系列标量优化,整理生成目标无关的LLVM IR代码。这段代码包括循环变量的递增、元素指针的计算及加载与存储操作,以及一个专门的浮点乘加内建函数调用。传统矢量化流程会直接依赖IR分析,但借助VPlan,LLVM将循环转换成更高层的规划表示,便于后续的矢量化转换。 VPlan中每条指令被赋予特殊的注释或标签,如ir<变量>指代原始IR中的变量,vp<变量>代表矢量化规划中新增的变量。
指令本身会被标记为广播、克隆(clone)、宽化(widen)等操作,统称为"recipes"(配方),这些配方指导最终LLVM IR的产生。 具体来看,在saxpy的规划过程中,循环计数和归一化归纳变量被转换为CANONICAL-INDUCTION和SCALAR-STEPS两种关键指令,表明循环将以VF为步长进行执行。对于内存访问操作,如getelementptr,采用克隆策略以保证指针正确递增,但不执行宽化操作。而对load、store及内建函数调用则执行宽化,以实现并行负载和计算。VPlan中的branch-on-count配方则维护了循环的条件跳转,并与抽象化的矢量访问计数保持一致,使得整个流程能灵活调整矢量因子。 经过若干优化阶段,VPlan会将需要的标量操作广播(broadcast)到整个向量,支持标量与矢量操作混合。
例如,标量系数a会通过broadcast指令复制为一个四元素向量,确保乘加指令的正确执行。广播操作本身在最终转换为LLVM IR时通过插入和重排元素指令实现,体现了LLVM IR内部强大的可表达能力。 VPlan的引入避免了传统矢量化中频繁直接操作IR所带来的复杂和易错问题。通过在更高层的抽象中描述矢量化计划,编译器能够更清晰地表示循环相关依赖、指令宽化及多重展开策略,同时也能动态评估不同参数的成本,选择最优计划。此设计显著提升了自动矢量化的适应性和性能。 此外,VPlan体系结构方便引入前沿的矢量化改进,例如智能规划不同宽度及展开因子的组合方案,实现多级矢量化支持。
未来,随着硬件向量指令集的不断丰富和异构计算的发展,VPlan的灵活性必将为LLVM在高性能计算领域提供更强有力的技术支持。 总体而言,LLVM中VPlan的设计体现了现代编译技术中抽象层提升与策略规划重要性的结合。它不仅系统规划了矢量化的步骤,也通过插装指令配方和动态参数评估带来了更优的代码生成效果。对于编译器开发者和性能优化专家来说,深入理解和掌握VPlan机制,有助于更高效地实施和扩展自动矢量化,释放硬件矢量执行单元的潜力,推动软件性能的跨越式提升。 。