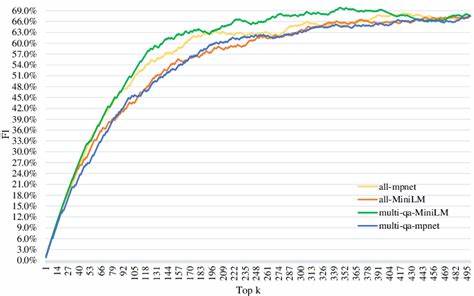
随着人工智能和自然语言处理技术的飞速发展,信息检索系统的智能化水平得到了极大提升。在众多技术手段中,嵌入式表示法(Embedding)因其能够将复杂的文本、图像及多模态数据映射到低维向量空间,从而捕捉数据内在语义关系,成为优化检索效果的重要方法。然而,随着嵌入模型的日益多样化和复杂化,如何合理评测其检索性能,保证搜索结果的准确性与效率,成为业界亟需解决的难题。这时,检索嵌入基准(Retrieval Embedding Benchmark,简称RTEB)应运而生,成为衡量和比较嵌入模型在检索任务中表现的标准化工具。检索嵌入基准的核心价值在于为不同嵌入模型提供统一、客观的评测体系,通过多样化的测试集和指标体系,揭示模型在实际检索环境下的适应性和优劣。以往,信息检索往往依赖传统的词频统计和关键词匹配方法,往返检索质量难以突破瓶颈。
而基于嵌入的深度语义匹配能够在语义层面捕获文本之间的细微联系,实现“以意达意”的检索体验。检索嵌入基准不仅考察模型的语义表达能力,同时注重模型在处理长文本、多语言以及噪声数据时的鲁棒性。这其中,评估维度涵盖准确率、召回率、均值平均精度(MAP)以及查询响应时间等关键指标,全面反映模型在工业应用中的实用价值。近年来,随着BERT、GPT等预训练模型的兴起,基于深度神经网络的嵌入方法逐渐成为研究热点。检索嵌入基准汇集了不同网络结构与训练策略生成的向量表示,对比分析其在真实检索任务中的表现差异。通过精心设计的任务集合,基准测试不仅涵盖简单的文本匹配,也涉及跨模态检索、多轮交互和个性化推荐等复杂应用场景,为算法研发提供最具针对性的指导。
值得注意的是,检索嵌入基准在社区生态的活跃推动下不断演进。开源平台和竞赛机制鼓励研究者分享最新成果,推动模型架构持续迭代优化。同时,标准化的数据接口和评测流程降低了模型集成与对比的门槛,加速了技术落地进程。此外,检索嵌入基准在商业应用中展现出广泛潜力。无论是电商搜索、社交媒体内容推荐,还是知识问答系统,准确高效的嵌入检索都能显著提升用户体验,减少信息过载,增强用户粘性。企业通过基准结果选用和调优模型,实现个性化搜索和智能客服等功能,增强市场竞争力。
未来,随着多模态数据的爆炸式增长和用户需求的多样化,检索嵌入基准将继续适应新技术趋势,融入更多场景下的评测需求。同时,融合知识图谱、多任务学习与联邦学习等技术,有望进一步提升嵌入模型的泛化能力和隐私保护水平。科研与产业界的紧密合作,将推动检索嵌入基准成为智能检索系统不可或缺的核心组件。综上所述,检索嵌入基准作为衡量检索效果的关键工具,不仅帮助研发人员明确模型优劣,指导算法优化,更为构建智能、高效的搜索引擎提供坚实基础。随着相关技术的不断成熟,检索嵌入基准将在推动信息检索技术革新和创新应用中发挥不可替代的重要作用,为人类信息文明进入新时代贡献力量。