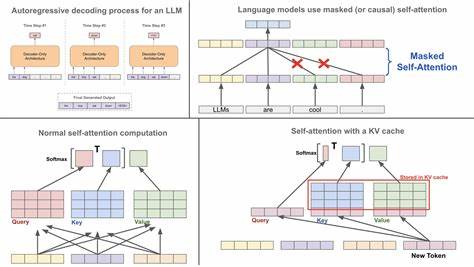
近年来,Transformer架构在自然语言处理领域取得了革命性的进展,尤其是在大型语言模型(LLMs)如ChatGPT、Llama等中表现卓越。然而,传统的Transformer在处理长文本序列时,计算复杂度呈平方级增长,导致其效率和性能在长上下文任务中面临严重瓶颈。众多研究尝试通过稀疏注意力、线性化注意力以及低秩矩阵分解等方法降低这种负担,但每种方法或多或少存在着信息丢失或上下文捕获不足的问题。CacheFormer的提出,正是针对这一关键挑战,通过灵活结合多种注意力机制和智能缓存策略,提升模型在长序列理解和生成中的表现。CacheFormer的设计灵感来源于计算机科学中的缓存(cache)和虚拟内存机制。计算机在发生缓存未命中时,不仅读取所需数据,还会预取邻近数据,以提升未来访问的效率。
类似地,CacheFormer将长文本序列划分为多个小段(segments),并根据压缩级别的段级注意力动态识别高关注度片段,以未压缩形式检索这些关键段及其相邻段,实现对重要上下文的精细处理。CacheFormer的整体架构由四种注意力机制有机结合组成。短期滑动窗口注意力负责捕获局部上下文关系,确保对近邻词汇的高效关注。长距离压缩段注意力通过对输入序列分段压缩后进行全局建模,降低了计算开销。基于动态top-k高关注度的未压缩段缓存机制,保障了模型关键语义信息的完整获取,避免了压缩带来的信息丢失。最后,长段重叠注意力通过半重叠的方法减少段碎片化问题,提升了上下文连续性的表达能力。
这种多重注意力的融合,不仅丰富了模型的上下文视野,也平衡了计算资源与建模精度之间的矛盾。CacheFormer在核心的自注意力计算上,采用段级注意力的方式有效降低了传统Transformer的On2复杂度。通过对长序列分段压缩,计算复杂度降至Onr(r远小于n),而动态缓存机制又保证了对于高影响力信息的精细表达,提升了整体语言建模质量。在公开数据集WikiText-103上的实验结果表明,CacheFormer相比于传统长短Transformer和其他SOTA模型,拥有超过8.5%的困惑度降低,显示出更强的文本预测能力。此外,在字符级语言建模的enwik-8数据集上,CacheFormer也展现稳定的性能优势。CacheFormer还特别针对“长距离依赖”的经典瓶颈提出解决方案。
以往模型在处理位于长文本中间部分的关键信息时表现较差,“中间遗失”现象严重。而CacheFormer通过动态选择高关注度段,无论该段位置在文本开头、中部还是结尾,都能以未压缩形式被模型充分利用,提升了模型对全文整体信息的把控。CacheFormer的实现过程兼顾了效率和性能。虽然动态缓存机制带来一定训练开销,但作者通过先预训练无缓存结构再微调启用缓存方案,有效平衡了训练资源的投入。架构中的段大小、压缩比率、top-k选择等超参数均可根据具体任务灵活调整,保证不同应用场景下的最佳表现。该模型的所有代码均已在GitHub开源,方便研究人员和工程师验证与复现。
CacheFormer不仅解决了长文本上下文建模中的性能与效率矛盾,也为未来语言模型的发展指明了方向。通过借鉴计算机架构中成熟的缓存原理,模型能够智能识别并缓存关键上下文,高效释放计算资源,避免无效信息的冗余处理。这一思路不仅适用于纯文本语言模型,也具有广泛的多模态序列处理潜力。展望未来,CacheFormer团队计划进一步优化多注意力机制的运行效率,探索更大规模模型和更复杂任务的应用,例如法律文档摘要、科学论文解读及代码分析等领域。层级缓存设计的引入也将助力应对超长文本的挑战,推动大型语言模型更好地适配现实世界的复杂文本环境。综上所述,CacheFormer以其新颖高效的段缓存策略,成功解决了Transformer长序列建模中的核心难题,实现了显著性能突破。
其多机制融合的创新理念为自然语言处理提供了一条兼顾准确性和计算效率的可行路径,具有重要的学术价值与实用潜力。随着相关技术和硬件的进步,CacheFormer有望成为未来高性能语言模型不可或缺的关键组件。