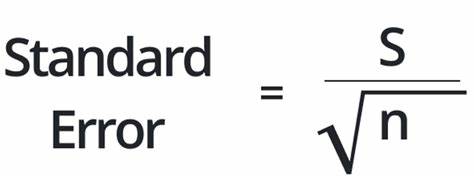
近年来,随着人工智能特别是机器学习的飞速发展,学术界和工业界对实验结果的可靠性提出了更高的要求。标准误差这一统计学概念被频繁提及,成为论文评审和实验论证的重要指标。然而,究竟什么是标准误差?它为何在机器学习社区产生如此持久的争议?其背后的逻辑与实际意义又是什么?本文将深入探讨这些问题。标准误差,顾名思义,是对估计参数不确定性的量度。简单来说,当我们执行多次实验或采样时,结果并不会完全相同,标准误差即用于描述这些实验结果的平均值与真实值之间的波动大小。在传统统计学中,标准误差帮助研究人员判断一个估计值的准确性和稳定性,进而推断其是否具有统计显著性。
然而,机器学习中的数据模式和实验设置往往复杂多变,不是所有情况下传统的标准误差计算方法都适用。以NeurIPS会议对论文的严格要求为例,近年来其对统计指标的规定逐渐趋严。从最初简单询问是否报告误差条开始,发展到细致要求披露误差来源、计算方法、统计假设、误差条的性质及置信区间等。表面上看,这种细化有助于增加实验透明度,但其背后的动因与效果却有争议。部分学者认为,机器学习实验中随机性确实存在,如模型参数初始化、数据划分、随机种子等因素都会影响结果,因此统计度量能提供对结果稳定性的基本保证。尤其是在面对部分数据集规模较小或设计多变的情况下,误差条能够让人更好地理解模型表现的波动范围及可信度。
这一观点强调了科研严谨性和对不确定性的量化,具有积极意义。相反,也有人质疑标准误差及其复杂规约的实际价值,甚至认为这是学术界过度形式主义的体现。机器学习的突破往往源于直觉和经验的积累,而非完美的统计假设支持。有时,强调标准误差带来的“准确度”反而掩盖了方法创新的本质。此外,许多机器学习实验的随机性并非完全服从正态分布,使用传统统计方法可能导致误导性的结论。比如某些自然语言处理任务的数据集极小,所计算出的置信区间并不具有普适推广意义。
更有批评人士指出,NeurIPS的统计规则在表面上强调严谨,却又不强制代码公开,导致实验难以真正复现,这种“打勾式”的流程更像是流程上的应付,而非实质上的质量保障。此外,NeurIPS等会议背后深厚的工业利益链也使得一些学者对其实验透明性及统计审查的效能持怀疑态度。总体而言,机器学习研究中的标准误差并非一成不变的“真理”,而是一套用于帮助理解实验结果不确定性的工具。它在不同的研究场景和数据结构下具有不同的适用性和限制。对于学者来说,理解其统计基础和潜在假设,合理使用和解读标准误差才是最重要的。只有这样,才能避免陷入过度形式化的束缚,也防止因忽视变异性而导致结论过于自信。
对于机器学习社区而言,或许更开放和灵活的统计使用指导,而非庞大复杂的强制性检查表,会更助于健康科研生态的建设。统计学本质上是对现实世界不确定性的数学描述,它不能取代对模型和数据的深刻洞察。未来,如何在统计严谨性与实际创新之间达成平衡,将是机器学习领域不可避免的难题。研究人员和会议评审者应当意识到统计工具的双刃剑属性,既要尊重其固有价值,也要警惕其被制度化滥用的风险。与此同时,推动开源代码和实验复现的规范,才是确保研究透明度和可靠性的根本之道。随着人工智能应用越来越广泛,机器学习社区对标准误差及其他统计指标的认知和实践仍将继续演变。
这场关于统计“真谛”的辩论,也折射出整个领域在技术创新与科学方法论之间的拉锯。理解并接纳这种复杂性,才能在未来的算法设计和评估中更加游刃有余。