引言 在构建基于大语言模型的检索增强生成系統(RAG)或问答服务时,常被忽视但极为关键的一点是:以何种格式把表格数据交给模型。格式选择不仅影响模型能否正确读取和定位数据,还直接决定了处理代价与系统最终的可靠性。近期一项对 11 种常见数据格式的对比测试,揭示了格式差异会带来显著的准确率与令牌成本差别,对工程实践具有重要参考价值。 为什么表格格式如此重要 许多现实应用需要将大量结构化记录传入 LLM,典型场景包括客服知识库、企业人力资源查询、财务报表问答等。如果格式不利于模型解析,模型可能出现抽取错误、混淆字段或直接失败,进而降低系统整体准确率。此外,格式差异会影响表示同一数据所需的令牌数量,从而影响推理成本。
换言之,正确选择或转换格式可以在保证更高准确率的同时节省成本,属于低成本高收益的工程优化路径。关键词包括 LLM、表格格式、CSV、JSON、Markdown-KV、准确率、令牌成本、RAG 与提示工程。 实验概述与测试设计 研究团队用合成数据生成了 1,000 条员工记录,每条记录包含 8 个字段:ID、姓名、年龄、城市、部门、薪资、工作年限与项目数。对每种格式,向 GPT-4.1-nano 传入全部记录并随机生成 1,000 个检索问题。每个问题对应检索某条记录的某个字段值,模型需要返回精确数值作为答案,便于量化准确率。测试目的在于衡量 LLM 在不同文本化表示下检索具体字段值的能力,并同时记录处理所消耗的令牌数以评估成本。
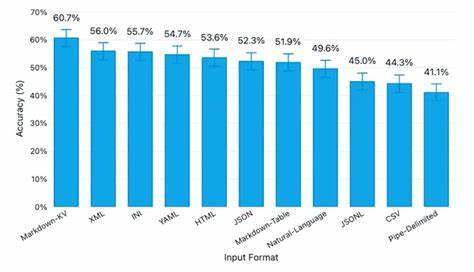
参与比较的 11 种格式包括 JSON、CSV、XML、YAML、HTML、Markdown 表格、Markdown-KV(即键值块风格)、INI、管道分隔、JSONL 与自然语言描述。值得注意的是,Markdown-KV 在实验中指的是使用键: 值块放在独立记录区域的风格,类似于逐条展示且带明确键名的格式。 关键实验结果 实验显示,不同格式的理解准确率有显著差距,同时不同格式在令牌占用上也差异很大。总体结论可以用两点概括:一是格式选择会对模型检索字段值的成功率产生实质影响;二是通常更"冗长"或结构清晰的格式会提高准确率但也增加令牌成本。 具体数值层面,Markdown-KV 在本次实验中表现最佳,平均准确率为 60.7%,处理所用令牌约为 52,104。位居其后的是 XML,准确率 56.0%,令牌约为 76,114。
INI 与 YAML 分别达到 55.7%(48,100 令牌)和 54.7%(55,395 令牌)。HTML 准确率 53.6%,令牌约 75,204。JSON 的准确率 52.3%,令牌约 66,396。Markdown 表格准确率 51.9%,是较为节省令牌的格式之一,令牌约 25,140。以自然语言段落描述呈现的数据准确率为 49.6%,令牌约 43,411。JSONL 与 CSV 在这套测试中表现较差,分别为 45.0%(54,407 令牌)和 44.3%(19,524 令牌)。
管道分隔格式位列末尾,准确率 41.1%,令牌约 43,098。 从置信区间角度看,实验给出了 95% 的置信区间范围,表明这些结果具有统计意义上的可比较性,但也提醒我们结果并非对所有模型或所有数据分布都绝对适用。 令牌成本与准确率的权衡 实验还显示出令牌使用量与准确率之间的一般正相关关系。更结构化、冗长或在视觉上更"显式"的格式往往为模型提供了更清晰的线索,从而提高检索成功率。但这种相关性并非严格线性,存在一些表现优于其令牌消耗的"高性价比"格式,例如 Markdown-KV 在相对中等令牌消耗下取得了显著领先。相反,某些格式在令牌效率和准确率上都表现不佳,例如管道分隔格式既未能节省大量令牌,也没能提供高准确率。
工程实践建议 在工程实现层面,如何根据应用场景权衡格式选择值得关注。若任务对准确率极其敏感,例如医疗记录检索、法律条文查证或财务关键值核对,推荐考虑将数据先转换为键值块风格的表示,例如 Markdown-KV 之类。键值块能够明确呈现每个字段名,且通常把每条记录分隔开来,有利于模型在上下文中精确定位目标字段。 若对可读性与成本有平衡要求,例如构建面向人类审核的问答界面或需要频繁人工检查的系统,Markdown 表格是一个折中选择。Markdown 表格既具可视化表格头的优势,也通常比 JSON 或 XML 更节省令牌。 应对 CSV 与 JSONL 的常见误区时需谨慎。
尽管 CSV 与 JSONL 在数据工程流水线中极为常用且易于程序化处理,但实验显示它们在直接传给 LLM 以进行字段检索时可能导致较低准确率。若必须使用这些紧凑格式,可以考虑在传入 LLM 前做格式增强,例如定期重复表头、添加字段注释或将紧凑记录转换为更显式的键值块。 实际工程中还应结合以下策略以提升整体效果。首先进行检索或筛选,把只有相关的子集传给 LLM,避免把上千条记录直接塞入上下文。对大型表格,分块传输并在每块中重复标题可以显著提升模型对列名与数值的对应感知。构建明确的提示词(prompt),在 prompt 中再次列出目标字段名以及期望回答的格式(例如只返回数字),能减少模型生成噪声。
最后,在模型输出后加入简单的规则校验与类型转换,确保数值型字段满足格式与范围限制,从而提高系统可靠性。 示例与实施细节 在实际系统中可采用的做法包括:先用检索器(向量搜索或 SQL 过滤)定位可能相关的记录,再把这些记录以 Markdown-KV 或结构化键值块的形式传入 LLM;对每一批次在顶部提醒模型字段名和返回规范;设置回答验证逻辑,例如正则验证是否仅返回数字或检查薪资数值是否在合理区间。上述方法能把模型的"上下文注意力"聚焦到真正关键的字段上,从而提高命中率并减少不必要的令牌消耗。 方法论与局限性 尽管实验结果提供了有价值的指导,但需要理解其局限性。首先,实验仅使用了 GPT-4.1-nano 这一型号,不同型号或不同厂商的模型可能在训练数据与偏好上有差异,最擅长的表现格式也可能不同。其次,测试数据是合成且模式一致的表格,现实中的数据可能包含嵌套结构、缺失值、合并单元格或多层级元数据,复杂性更高。
第三,测试问题都属于直接检索字段值的类型,若问题类型涉及统计推断、聚合或跨记录推理,格式偏好可能不一样。最后,为了制造压力场景,测试把 1,000 条记录一次性传入模型且没重复表头,实际生产环境中常常会把数据分段并重复标题,这会提升某些格式(如 CSV、Markdown 表格、HTML 表格)的表现。 未来研究方向 未来可以在多个维度上扩展研究深度。可以把更多模型纳入对比,包括开源模型与其他商业模型,以观察不同训练数据与架构对格式偏好的影响。可以尝试更复杂的数据结构,例如嵌套 JSON、带注释的配置文件或跨表关联查询,考察模型在不同表示下的解析能力。还可以研究不同问题类型的表现,例如聚合统计、条件过滤、模糊匹配或多条记录综合推理等。
此外,新出现的表格格式或轻量化的规范化表示(例如业界正在关注的 TOON 格式)也值得纳入评估。 结论与落地要点 格式选择对 LLM 的表格理解能力有显著影响。实验结果建议在追求最高准确率时优先考虑键值块风格的表示,尤其是 Markdown-KV 这样的显式键值分块。当需要在可读性、开发便利性与成本之间权衡时,Markdown 表格提供了不错的折衷。对 CSV 和 JSONL 的直接使用需要谨慎,建议在传入模型前进行增强或转换。无论选择何种格式,结合检索预筛、分块传递、提示工程与输出校验等工程实践,才能在现实系统中取得更稳定的效果。
对工程团队的简明建议是:把数据格式作为可调参数纳入性能测试流程,用目标模型进行 A/B 测试以找到在具体任务、数据分布与成本约束下的最优表示。通过小规模试验验证格式转换是否能显著提升关键任务的准确率,然后再在生产流水线上推广。这样可以用有限的工程投入换取显著的准确率提升与成本优化。 结语 表格不仅仅是数据的容器,其文本化表示会影响大语言模型的注意力、抽取能力以及最终输出质量。通过对格式敏感性的认识与工程实践的应用,团队可以在不改变模型主干的情况下获得可观的性能提升。随着更多新格式的出现与更多模型的测试,推荐把"表格格式优化"作为构建可靠 LLM 系统的常规工作之一,以实现更高效、更可信的智能检索与问答体验。
。