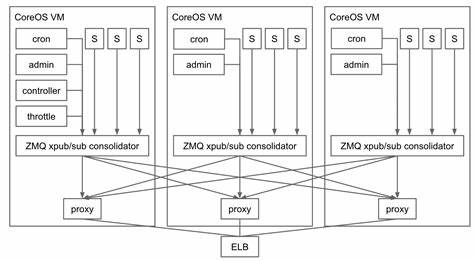
在当今数字化时代,声音合成技术取得了飞速提升,AI生成的声音越来越接近真人发声,甚至有时让人难以察觉其中差异。无论是在客服、虚拟助手还是娱乐产业,AI声音的广泛应用带来了便捷,同时也引发了人们对声音真实性的关注和辨别能力的考验。是否能够分辨人类的声音和由人工智能合成的声音,不仅是一场听觉上的挑战,更牵涉到信息安全和信任的核心问题。本文将深入探讨人声与AI声音的主要区别,剖析背后的技术原理,并通过一场听觉测验,帮助你提升对声音真假辨别的敏锐度。 人类声音的独特魅力源自复杂的生理结构和情感表达。声带振动、口腔形态、气流控制以及说话者的情绪,都赋予了人声天然的多样性和细腻感受。
人声拥有自然的停顿、节奏和韵律,甚至包含微妙的失误或呼吸声,这些细节无意中构筑了真实性。而AI声音合成虽然通过深度学习和神经网络模拟了大量人声特征,但仍存在一定的机械感,例如语音的连贯性、情感深度和自然流畅度上难以完全复制人类的复杂情感。 AI合成语音技术主要有两类,一类是基于拼接的传统方法,通过剪辑真实人声片段拼接生成,另一类是基于深度学习的神经网络模型,能够生成连续且高度拟真的语音流。后者技术依赖海量语料库训练模型,模拟人声的音高、语调、停顿等特征,实现更为自然的表现。这些模型包括WaveNet、Tacotron以及最新的Transformer等架构,不断推动语音合成迈向人声真品级别。然而,尽管技术先进,AI声音仍可能在极为细微的发音和情感表现上暴露端倪。
在个人和社会层面,能够准确鉴别人声与AI声音的能力越来越重要。虚假语音可能被用于诈骗、假新闻传播甚至身份伪造,造成严重的安全隐患。同时,企业在客服和品牌传播时合理使用AI声音,有助于提升服务效率,但也需避免误导用户。针对这些挑战,不少平台和研究机构开发了声音辨别的在线测试和小工具,鼓励用户通过日常练习提升识别能力。 进行AI声音与人声的辨别测试,首先需要集中注意力捕捉细腻的语音细节。人类声音在语气变化、情绪表达方面稍显丰富,往往伴有微小调整和情感波动。
而AI语音虽然在语法和语音清晰度上表现突出,但偶尔存在语调过于平坦或情感不足的现象。此外,AI生成的音频有时会在极短时间内出现轻微的音质波动或重复音节,这些隐蔽的提示有助于判定其真实性。 在实践中,提升辨别技巧可以通过反复聆听多种类型的声音样本来实现。结合对话语境和声音特征分析,比如观察停顿位置、重音控制以及音调起伏,会发现更多蛛丝马迹。有些专业工具还结合人工智能辅助检测技术,从频谱分析、音频结构等科学层面辅助判断真假。 未来随着AI生成声音技术的不断进步,辨别难度也会持续加大。
这要求公众不仅依赖耳朵感知,更要结合更多验证手段,如声源追踪、上下文验证与多因素鉴别。同时,科技公司、监管机构也需加强合作,确保相关技术的透明度和合法性,规范AI声音的使用场景,防止不法分子滥用,降低社会风险。 在数字交流日益频繁的今天,人类声音的真实性是构建信任的基石。通过不断学习和锻炼辨别真假声音的能力,用户不仅能保护自己免遭欺诈,也能更好地理解和利用AI声音技术带来的便捷和创新。当你下次遇到一个声音是否来自真人时,不妨来参加相关的声音辨别测验,挑战你的听觉敏锐度,感受科技带来的变革同时守护交流的真诚与安全。 。