近年来,大型语言模型(Large Language Models,简称LLMs)以其强大的自然语言理解与生成能力,迅速引起了软件工程领域的广泛关注。尤其是在代码生成和辅助开发方面,许多人对其抱有极高期待,认为它们能够大幅提升开发效率,甚至替代部分人类工程师。然而,事实究竟如何?LLMs究竟能在多大程度上胜任复杂的软件工程任务?关键的影响因素又是什么?其中“聚焦与语境”成为无法绕开的核心命题。 作为一位从2020年8月便开始深度应用LLMs的实践者,作者Taras Glek分享了他的真实体验和思考。他最初被GPT-3破解SQL语句生成难题的能力所震撼——过去需要花费4-8小时查阅文档和调试的代码,现在借助LLM仅用15分钟便可完成。这一体验展示了LLM在简化重复且结构化任务上的巨大潜力。
然而,他在后续的实际工作中,尤其是尝试构建端到端的软件项目时,逐渐意识到事情远没有表面那么简单。 网络上流传着各种“agentic编码”工具和思潮,声称可以自动完成多版本复杂软件开发,颇具“兴奋剂状态下的多动症代理”的夸张感。这种较为浮躁的认知实际上误导了许多开发者,对LLM能力的预期偏高,甚至忽视了其核心限制。尽管业内普遍盛传LLM或有望取代大量工程师的观点,但实际上,顶尖项目如今寥寥可数。作者仅了解过一个被广泛认可的完整案例:基于Gemini 2.5 Pro打造的符合标准、100%由LLM生成的HTTP/2服务器。 该项目的成功背后是一系列严密的工程实践,而非纯粹依赖模型自身的“自由发挥”。
作者花费了大量时间和精力,为LLM提供精确的上下文信息,维持模型持续的工作反馈,设计了分而治之的测试流程,并创新地利用文件作为工作单元来管理上下文。令人大跌眼镜的是,传统令人期待的官方“工具调用”功能反而难以胜任此类任务,作者也因此称其为当下agentic编程的短板。 此外,撰写格式化严格的JSON输出对模型而言是极大挑战。很多时候,非结构化但模型熟悉的自定义格式才更易达成生成目标。这说明当前LLM训练和推理机制还未真正适配复杂且规范严苛的编程需求。 整体来看,从项目启动到最终完成花费数周时间,而且需要作者及其团队持续介入、细致控制每一个生成环节。
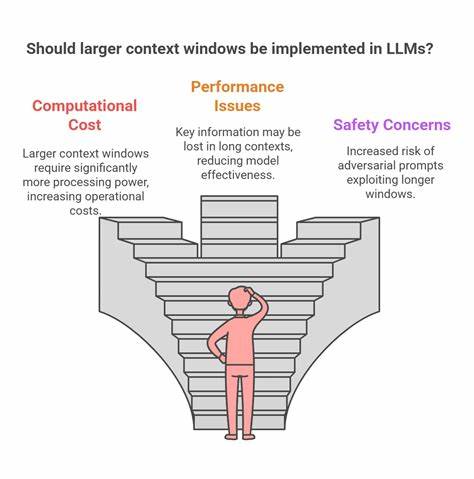
这显现的是,与其让LLMs像“自由代理”一样自发运作,不如将它们视作需要严密监督和辅助的协同工具。换句话说,在算法层面实行精细的上下文管理和迭代策略远比单纯依赖“自动大爆炸”来得实用有效。 这正戳中了一个根本性难题:LLM产出质量与输入的上下文信息紧密相关。无论是初始问题、提示词设计、输入环境,还是围绕任务的背景知识,都是决定模型表现的关键因素。现有agentic编程尝试往往如同90年代的遗传算法热潮,拼命用暴力暴力搜索的方式求解,但成本高昂且效果难以令人满意。 因此,除非能、并能够专门设计更佳的上下文策划及维护手段,否则LLMs的强大全面能力只能在极少数经验丰富、技术过硬的软件工程师的手中得以充分发挥。
那些缺少对背景信息敏感度和输入优化意识的使用者,很可能仍旧只能得到表现平平的结果。 进一步的案例研究和业界反馈也支持这一观点。谷歌官方的一篇博客反思了他们AI在上下文处理方面的难点,http://rjp.io上的相关博文也指出,耐心与策略的结合在利用LLM代理时至关重要。甚至,过多的上下文信息亦可能成为负担,导致模型难以聚焦关键目标,从而降低输出的有效性。 总结而言,当前阶段的LLMs尚未迈入能够广泛解放工程师、实现真正低监督自动编程的时代。它们更像是需要精心指挥的“高性能辅助机器人”,依赖着精准、丰富且经过加工整理的上下文资料。
开发者面对模型数据时的聚焦度、选取信息的合理性、上下文切分和动态反馈及纠错机制,才是影响最终结果的关键。 未来,科研和工程界应当探索更加智能化、主动化的上下文管理技术,如智能知识库融合、实时上下文更新、跨模块语义联结等,从根本上提升LLM的理解深度和执行力。与此同时,培养用户对语境敏感和工程化思维的结合能力也至关重要,只有人与模型协同,实现优势互补,才能最大限度地释放大型语言模型的潜能。 当下的技术发展尽管充满挑战,但LLMs无疑为软件工程带来了新的思考维度和工具选择。合理定位它们的作用边界,克服上下文瓶颈,是业界迈向下一代高效智能开发的必经之路。随着方法论逐步成熟,期待更多突破为软件创新注入源源动力。
。