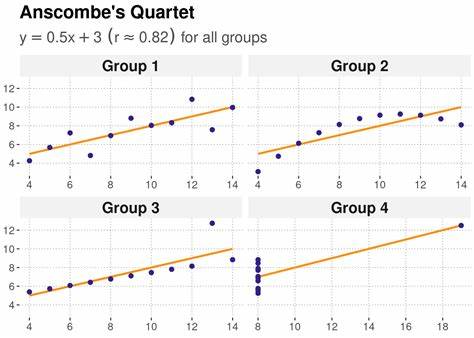
在数据分析领域,安斯科姆四重奏(Anscombe's Quartet)作为一个经典案例,被广泛用于说明简单的统计指标可能掩盖数据背后的真实结构。安斯科姆四重奏由四组各包含十一对(x, y)数据点的数据集组成,这四组数据在均值、方差、相关系数以及回归线等基本统计参数上几乎完全相同,然而它们的散点图却各不相同,展现出完全不同的数据分布形态。这个设计巧妙地表明,单一依赖数值统计可能让分析者忽视数据的真实情况,从而导致错误的推断。 安斯科姆四重奏的背后,是统计学家弗朗西斯·安斯科姆为反驳当时部分统计学家只信赖数值计算而忽视图形分析的流行观点而构建的。安斯科姆指出,数值计算的准确虽然重要,但图形展示同样不可或缺,优秀的统计分析应两者兼顾。四组数据的统计指标都显示:x的平均值均为9,样本方差为11,y的平均值约为7.5,样本方差约为4.125,x和y的相关系数均为0.816,线性回归方程也都是y=3.00+0.5x,线性回归的决定系数R²约为0.67。
尽管这些统计特点相同,四组数据的散点图却截然不同。 第一组数据的散点图显示了明显的线性关系,点大致沿着回归线均匀分布。这种表现是大多数统计分析中理想的情况,x与y之间线性相关且没有异常值干扰,因此统计数值与图形表现是相符的。 第二组数据的图形则表现出明显的非线性关系。数据点分布呈现曲线趋势,简单的线性相关无法全面捕捉这种关系。这里,标准的皮尔逊相关系数变得不适用,更合适的做法是进行非线性回归分析,以揭示变量间的真实关系。
尽管统计上的相关系数一致,单靠数值指标会使人误以为线性模型足够准确,忽略了数据的曲线走势。 第三组数据体现了线性趋势,但含有一个显著的异常值,这个异常点对整体的回归线和相关系数产生了较大影响。该异常点拉低了总体的相关系数值,使之从理想的1降至0.816。这种体现展示了异常值在统计分析中的"杠杆"效应,稍加注意和适应性处理,如稳健回归方法,可以有效降低个别异常点的干扰。 第四组数据则更为极端,几乎所有数据点都堆积在同一个x值附近,只有一个特殊的数据点横跨了较大的x值范围。这使得该点成为高杠杆点,对统计参数产生巨大影响,导致整体相关系数依然维持较高水平。
换言之,相关系数的高值完全是由唯一的高杠杆点所驱动,而非其他观察值之间的真实关系。这种情况提醒我们,在分析数据时,仅凭相关系数来判定变量间相关性可能会产生误导,必须结合图形和背景知识进行综合判断。 安斯科姆四重奏的意义不仅在于警示统计分析中的常见误区,更促进了现代数据分析中可视化方法的重要发展。随着计算机技术的进步,数据可视化已成为数据科学的基石,能够帮助分析师直观理解数据结构、检测异常值和识别非线性关系。即使是在大数据和机器学习盛行的今天,安斯科姆四重奏依旧被广泛应用于统计课和数据科学教学中,用以强调"简单统计量不足以描述复杂数据"的理念。 此外,围绕安斯科姆四重奏的思想,研究人员发展出了许多类似的案例,用以说明数据的多样性和隐藏的复杂性。
例如,Datasaurus Dozen通过设计数据点绘制出恐龙形状及其他图形,所有数据集依然具有完全相同的统计特性,却视觉效果截然不同。这类作品极大丰富了教学与科研领域对于统计图形与数据结构关系的认知。 在实际应用中,安斯科姆四重奏对各种领域的数据分析方法具有启发作用。无论是经济金融领域的趋势判断,还是医学领域的临床研究,均需警惕因单一统计指标而忽视潜在数据结构的可能。同时,设计合理的数据验证过程,结合图形检验与数值分析,可有效避免模型失真和推断错误,提升研究质量。 总结来看,安斯科姆四重奏不仅仅是一组简单的数据集,而是对科学数据分析方法的深刻反思。
它教导我们要对数据进行多维度观察,不拘泥于简单的统计数字,结合图形展现与合理模型,方能抓住数据的真实内涵。未来,随着数据科学的不断进步,安斯科姆四重奏依然作为教育和研究中不可或缺的经典范例,启迪着下一代数据学者。 。