在当今数据驱动的时代,机器学习技术不断取得突破,广泛应用于医疗诊断、金融预测、自动驾驶等方方面面。有效选择算法与调优流水线成为提升模型性能的关键。然而,算法选择问题(Algorithm Selection Problem, ASP)面临着高昂的计算成本,因为研究人员需要在多个算法和数据预处理步骤之间反复实验。为了降低计算负担并加速实验进程,元学习(Meta-Learning)方法应运而生,它通过学习过往实验经验来预测算法表现。元学习的发展离不开高质量、多样且丰富的实验数据集。PIPES正是在这一背景下应运而生的创新性元数据集。
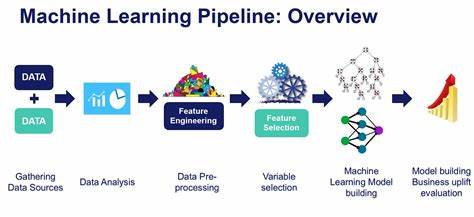
PIPES是一套涵盖多种机器学习管道组合的元数据集,由Cynthia Moreira Maia等研究人员打造。它通过执行超过9408条不同的机器学习管道,涵盖数据预处理、特征工程以及模型训练的多个步骤,应用于300个真实数据集上,积累了详尽的训练测试时间、预测结果、性能指标以及潜在错误信息。与现有资源如OpenML相比,PIPES在算法和预处理多样性方面表现突出,填补了传统数据集在管道设计上的局限,为研究者提供了一个更全面、更平衡的实验宝库。 在机器学习管道设计中,数据预处理是提升模型性能的根基。常见的预处理步骤包括数据清洗、缺失值填补、特征缩放、编码转换等。传统元数据集往往偏重少数几种预处理技术,导致实验样本在方法选择上存在偏差,限制了元学习模型推广的有效性。
PIPES系统地涵盖了多种预处理技术的组合,确保了数据预处理阶段的多样性,增强了实验结果的泛化能力。 此外,PIPES的实验设计注重平衡不同技术的使用频率,避免了单一流行技术占据主导地位的情况。这种均衡设计不仅提供了均匀的样本分布,也使研究者能够更深入探究不同管道组件的相互作用与整体性能。例如,在模型选择方面,不同算法在特征预处理配合下,可能表现出截然不同的适应性与稳定性,这为个性化算法推荐与自动机器学习(AutoML)系统开发提供了宝贵的数据资源。 PIPES元数据集的另一个亮点是其开放性和可扩展性。研究人员可以在现有基础上继续增加新的管道组合和数据集,推动元学习社区持续发展。
开源的代码库和详尽的补充材料为使用者提供了便利,降低了入门门槛,加速科研成果转化为实际应用。 通过利用PIPES,研究者能够快速开展跨数据集的性能分析,识别出最优的管道组合,进一步指导算法设计与选择。机器学习算法的效率不仅仅取决于单一模型的调整,更依赖于整体管道的优化布局。PIPES助力在复杂多变的现实场景中,挖掘最适合特定任务的管道配置,提升模型准确性,同时降低训练成本。 PIPES的诞生为元学习领域带来了一场范式转变。它使得以往需要大量手工设计与实验才能完成的管道探索,转变为依托大规模统一数据支持的自动化过程。
未来,随着机器学习应用的深化,管道的复杂性将持续提升,PIPES及类似元数据集将成为推动智能系统自适应和优化的核心资源。 总结来说,PIPES不仅是一个庞大且详尽的机器学习元数据集,更是一个促进创新、加速研究和应用的强大平台。它解决了传统元数据集在多样性和代表性上的不足,提供了横跨300个数据集的9408条管道实验,覆盖丰富的预处理和算法组合,为机器学习算法选择及管道设计奠定了坚实基础。随着开放数据和协同研究的深化,PIPES的潜力将不断释放,助力研究人员构建更高效、更智能的机器学习系统,推动人工智能领域迈向更高峰。 。