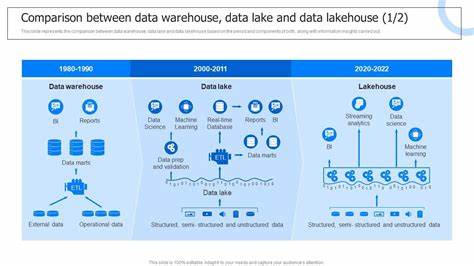
随着大数据时代的到来,企业对数据存储与分析的需求不断提升,如何高效管理海量数据成为技术发展的热点。数据湖仓(Data Lakehouse)作为一种融合数据湖灵活性与数据仓库结构化优势的革新型架构,逐渐成为数据管理领域的主流选择。2023年,针对三大领先数据湖仓系统——Delta Lake、Apache Iceberg和Apache Hudi的研究与比较为行业提供了宝贵的参考。本文将深入解读这三个系统的核心特点、性能表现及适用场景,助力企业在复杂数据生态中做出明智决策。数据湖仓的兴起本质上解决了传统数据湖和数据仓库之间的矛盾。数据湖以其对结构化及非结构化数据的高灵活度获取优势,为数据科学家和工程师提供广阔数据来源,但其缺乏严格的数据治理和一致的性能表现,使得查询效率及数据质量难以保障。
相反,数据仓库则强调数据结构化、事务完整性及优化查询性能,但在面对海量多样化数据时,成本与扩展性受到限制。数据湖仓系统试图通过统一架构,实现兼顾灵活性与一致性的最佳实践,既支持流式及批量数据摄取,又能确保数据一致状态和高效查询。Delta Lake作为Databricks推出的开源项目,以其强大的事务管理(基于ACID特性)和可靠的数据版本控制著称。其设计注重与Apache Spark的深度集成,能在大规模分布式环境中保障数据一致性和容错机制。实验表明,Delta Lake在多维度场景下均展现出稳定高效的查询能力,适合负载复杂、数据量庞大的企业级应用。然而其学习曲线较陡峭,尤其对于初学者而言,需要花费额外时间掌握其生态系统和操作方式。
Apache Iceberg作为Apache基金会支持的开源项目,采用表格式数据管理元数据,提供了高度灵活的数据摄取机制和优异的扩展性。通过创新的表格式存储方法,Iceberg能快速响应数据变更,支持多种查询引擎,对大批量数据摄取速度表现尤为突出。研究数据显示,Iceberg在处理高速数据写入时优于其他两个系统,展现出卓越的吞吐能力。更值得一提的是,其完善的文档和社区支持降低了用户的门槛,使得开发者更容易入门和实施。Apache Hudi同样是开源大数据存储框架,独特之处在于对实时数据流和增量数据的高效处理。Hudi提供了索引和压缩技术,特别适合处理小规模或中等规模数据集,能够实现快速增量查询和数据修改。
研究中发现,尽管其在超大规模数据处理上存在一定限制,但在专注于较小数据集的场景中表现优异,且对实时数据分析支持力度较大。相比之下,Hudi的实现复杂性较高,实际应用中可能面临配置调优难题。在数据摄取方面,Apache Iceberg因其卓越的数据写入速度脱颖而出,适合对数据更新频率和速度有较高要求的企业。Delta Lake凭借稳定一致的事务处理能力,适合追求系统稳定性和查询准确性的场景。Apache Hudi则更适合对实时数据处理和增量更新有强烈需求的小型或中型数据平台。查询性能方面,Delta Lake的表现一直保持在较高水准,能够应对复杂查询和大规模数据分析。
Iceberg虽然摄取快,但查询性能在某些复杂场景下略逊一筹。Hudi针对实时或近实时数据分析场景优化,适合特定应用但扩展性有限。系统易用性和实现成本也是考虑重点。Apache Iceberg通过良好的文档和简单明了的API设计赢得较高用户体验。Delta Lake虽然功能强大,但其较为复杂的生态系统和配置要求使初学者需要更多学习时间。Apache Hudi实施难度最大,技术门槛对团队能力提出较高要求。
总结来看,数据湖仓作为新一代数据架构,融合了数据湖的弹性与仓库的结构优势,三大系统各有千秋。Apache Iceberg在快速数据摄取和用户友好度上表现突出,适合注重灵活性和开发效率的团队。Delta Lake以其稳定一致的性能成为通用场景的坚实选择,适合复杂数据分析和企业级应用。Apache Hudi则在处理实时数据流和小规模数据集时具有独特优势。选择适合的系统应基于具体业务需求、数据规模及团队技术能力综合考虑。展望未来,数据湖仓技术仍处于快速发展阶段,随着功能完善和社区生态壮大,其在数据管理领域的地位有望进一步巩固。
企业应密切关注相关技术进展,结合自身业务特点,逐步推进数据湖仓系统的部署与优化,夯实数据驱动决策和创新的基础。