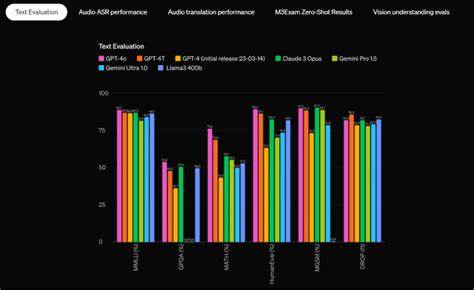
随着人工智能技术的快速发展,基础模型(Foundation Models)正以前所未有的速度渗透到各行各业,尤其是在情感计算领域展现出强大潜力。多模态视觉语言模型(Vision Language Models,简称VLMs)如今已经能够在零样本情境下实现面部情绪的识别,大幅提升了自动情绪感知的效率和准确度。然而,近期一项针对基础模型在面部情绪识别中的表现研究却提醒我们,这些模型在学习情绪信息时可能并不是基于真正的心理学依据,而更倾向于依赖于一些浅显、甚至是表面的视觉代理特征。研究集中分析了基础模型如何受牙齿可见性的影响,从而揭示了其潜在的代理偏差问题。这不仅关乎模型的性能,也引发了关于公平性、偏见和伦理性的深刻思考。 面部情绪识别作为情感计算领域的重要任务,旨在通过对面部特征的分析推断个体的情感状态。
传统方法往往依赖标注数据中预定义的面部肌肉动作编码系统(如FACS),结合机器学习模型进行训练。而基础模型如GPT-4o等大型多模态模型,则通过预训练和大规模数据学习,具备了跨任务、跨领域的泛化能力,可在缺乏明确标注的情况下,进行零样本的情绪推断。这种能力极大地拓展了情绪识别的应用场景,如心理健康评估、在线教育情感反馈、智能客服等。 然而,基础模型对视觉特征的解读方式并非完全基于心理学定义的情绪表达。研究发现,这些模型在面对AffectNet数据集中牙齿可见与否的变异时,其情绪识别表现存在显著波动。在该数据集中,牙齿的有无被专门标注,有助于理解模型是否将牙齿这一视觉线索作为情绪判断的重要依据。
实验结果显示,当牙齿明显可见时,模型倾向于将该面部表情与积极情绪或高活跃度联系起来,而在牙齿隐藏的情况下,情绪推断的准确性和一致性则下降。这表明模型在某种程度上依赖牙齿这一代理特征,作为情绪判断的捷径。 这种依赖现象带来的影响不可小觑。首先,它暴露了基础模型中存在的“捷径学习”(shortcut learning)问题。模型并非深度理解情绪背后的心理机制,而是抓取容易被机器学习到且与标签相关的浅表特征,导致在现实应用中可能出现误判或偏差。举例而言,不同文化背景下微笑的表达方式存在差异,牙齿是否外露并非情绪高低的唯一标志,但模型的偏好可能导致对非标准表达的误解。
其次,代理偏差问题还涉及公平性与伦理风险。情绪识别技术被广泛应用于敏感领域,如精神健康诊断、教育辅导甚至法律审判中,任何偏差都会对个体造成不公,甚至引发严重后果。如果基础模型偏重某些显著的视觉代理特征,忽略真正的情绪表达多样性,则极有可能加剧社会不平等。例如,有些群体因文化习惯或生理特征在表达微笑时牙齿不外露,模型可能系统性低估其积极情绪,从而产生辨识歧视。 为了更深入理解基础模型的情绪识别机制,研究团队对最优表现模型GPT-4o展开了结构化内省分析。分析显示,除牙齿可见性外,诸如眉毛位置这类面部属性在其情绪推断中扮演了关键角色。
眉毛的高度或形态变化与情绪中的愤怒、惊讶等维度紧密相关,而GPT-4o能够捕捉这些细微变化,展现出较高的内在一致性。尽管如此,依然存在对可见性特征的过度依赖,提示模型在情绪理解上仍具有局限性。 基础模型的这一行为特征体现了其“涌现性质”(emergent behavior),即复杂模型在大规模数据训练中形成的非显式策略。这种策略往往难以被传统解释方法捕捉,增加了模型安全性和可靠性评估的复杂度。为解决这一挑战,业界和学术界需联合推动模型透明性和可解释性研究,开发更符合心理学和社会伦理标准的情绪识别系统。 未来在基础模型的情绪识别领域,提升模型对情绪表达本质的理解而非简单视觉特征的捕捉至关重要。
研究人员应注重构建多样化、文化丰富的训练数据集,完善对复杂情绪状态的标注体系,同时引入多模态信息融合,如结合声音、语义上下文辅助判断,以减少对单一视觉代理特征的依赖。另外,通过对模型决策过程的开放式监测和偏差纠正机制,保障情绪识别技术的公平性和责任性。 面向产业应用,企业在部署基础模型进行面部情绪识别时,也应警惕潜在代理偏差带来的风险,采取严格的测试和验证措施,确保系统在不同人群、不同环境下具有稳定且公正的表现。尤其在医疗、教育等敏感领域,情绪识别结果需结合专业人士判断,避免技术滥用和误导。 总体而言,基础模型为面部情绪识别带来了前所未有的创新机遇,其强大的零样本能力和跨场景适应性提升了情感计算的实用价值。但代理偏差作为潜在隐患提醒我们,技术进步的背后仍需谨慎而科学的审核机制,确保人工智能在情绪识别中的发展能够真正服务于人类更全面、更公平的内心世界理解。
通过不断深化跨学科合作,结合心理学、计算机科学和社会伦理的智慧,未来人工智能有望实现更准确且人文关怀兼备的面部情绪认知。