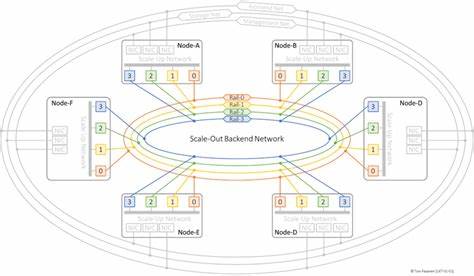
随着人工智能技术的飞速发展,AI集群作为支撑大规模深度学习训练与推理的核心基础设施,其网络架构设计的重要性愈发凸显。人工智能集群网络不仅直接影响训练效率和系统性能,还关系到资源利用率和扩展能力。本文将深入探讨AI集群的多层网络架构,重点解析Ultra Ethernet Specification(UES)及其对应的Scale-Out与Scale-Up网络,揭示如何通过优化网络连接实现低延迟、高带宽和可扩展的AI计算环境。 在AI集群中,最具代表性的网络类型包括Scale-Out Backend网络、Scale-Up网络、前端网络、管理网络和存储网络,每一种网络都承担着不同且不可替代的职责。Scale-Out Backend网络是跨节点GPU之间通信的纽带,其核心目的是实现低延迟且无丢包的远程直接内存访问(RDMA)消息传递,确保分布式训练时梯度同步及神经元激活函数结果的高效传递。基于Ultra Ethernet Consortium提出的Ultra Ethernet Transport(UET)协议,Scale-Out网络实现了从应用层到物理层全方面优化,确保AI和高性能计算(HPC)工作负载下的网络传输充分发挥GPU和RDMA-NIC硬件能力。
通过物理拓扑设计,Scale-Out网络常采用基于Clos架构的两层或三层交换结构,包括叶子交换机与骨干交换机,支持多路径、多组网路径分担大量长时间运行的数据流,极大提升了通信可靠性和带宽利用效率。网络流量特征方面,Scale-Out网络承载高延迟敏感且突发性明显的流量,典型的"象群流量"需要精准的拥塞控制机制以维持链路稳定。 与Scale-Out注重跨节点通信不同,Scale-Up网络专注于节点内部多GPU的高速互联。GPU厂商如NVIDIA和AMD提供的NVLink、NVSwitch和Infinity Fabric等专有技术,使得同一服务器内GPU之间可以通过低延迟、高带宽的专用互联通道直接访问彼此的显存,绕过主机CPU与系统内存,优化深度学习中的并行计算和数据共享效率。Ultra Accelerator Consortium新兴的Ultra Accelerator Link(UALink)标准则致力于提供开放的、厂商中立的200G速率GPU互联解决方案,进一步推动Scale-Up网络的标准化和多样化。Scale-Up网络中,拓扑结构可能是网格状或环形,也可能采用集中交换机架构,实现所有GPU节点对等且高速的访问性能。
通过这种直接且高效的数据交换模式,Scale-Up网络极大提升了训练过程中的集体通信能力,并降低了CPU负载。 前端网络则是用户与AI训练及推理系统交互的关键通路。通常采用可路由的Clos拓扑,支持高可靠性和大规模接入。为了满足多租户环境下的安全与隔离需求,采用了如BGP EVPN作为控制面,VXLAN作为数据面封装的虚拟网络技术。这使得不同用户和任务能够独立且安全地访问集群资源。同时,前端网络多基于TCP传输协议,速率一般为100G,且使用共享NIC连接,区别于单GPU独占的Scale-Out网络。
前端网络的通信模式多为短暂且高熵的小流,延迟敏感度适中,主要处理推理请求与任务编排,保持系统响应的灵活性与速度。 管理网络是AI集群后台的"大脑神经",负责集群调度、控制和运维。它连接管理服务器、计算节点以及辅助系统,如时间同步服务器、安全认证服务和远程管理接口。管理网络的流量带宽较低,但极为敏感,要求极高的稳定性与低延迟以保障集群的健康运行和操作连续性。为了避免与训练及推理数据流量混杂,管理网络通常采用物理隔离或逻辑分割(如VLAN/VRF)实现安全边界分明。典型应用包括作业调度与资源分配、训练任务初始化同步、固件和软件升级管理、监控与告警系统、远程故障排查等。
此外,管理网络的设计还强调高可用性和故障容错能力,确保任何时间点都能对集群状态进行有效掌控。 存储网络连接着各个计算节点与海量数据存储系统,保障训练数据集、模型检查点及推理数据的高速传输。其设计重点在于实现高带宽、低延迟及大规模扩展能力。常见支持协议包括NVMe over Fabrics(NVMe-oF)、光纤通道和支持RDMA的高速以太网。存储网络不仅负责高效的数据流动,还支撑数据预处理缓存、分布式训练的文件系统一致性以及模型部署后的数据落盘。由于训练数据规模庞大且访问频繁,存储网络对于整个AI集群性能和吞吐能力起到至关重要作用。
从整个AI集群的角度来看,网络设计的挑战在于如何在不同层次和场景下权衡延迟、带宽、可靠性和安全。Scale-Out网络需要搭建低延迟、无损耗的多节点GPU通信环境,尤其面对复杂的分布式训练负载时,网络拥塞控制和多路径路由设计是关键。Scale-Up网络依赖高速、专有或标准化的GPU间互联技术,实现节点内的快速数据交换,减轻CPU负载,同时需确保标准兼容和互操作性。前端网络承担用户入口任务,既要保障多租户安全隔离,也需提供交互响应速度。管理网络则是保障集群稳定运行的管理与运维保障,要求高稳定性和安全性。存储网络则涉及大规模数据访问和分发能力,是训练数据管理的核心环节。
Ultra Ethernet Specification的提出和推广,为AI集群网络的标准化和性能提升奠定了基础。通过定义专门针对RDMA优化的传输层协议Ultra Ethernet Transport(UET),以及从软件到物理层的全栈设计,UES增强了以太网在AI与HPC工作负载中的适用性。结合RDMA-NIC直接操作GPU显存的硬件加速优势,UES极大降低了通信延迟,使得大规模分布式训练和高密度推理计算成为现实。 未来,随着AI模型规模的不断扩大和计算需求的日益增长,AI集群网络架构将持续演进。更高带宽、更低延迟、更智能的网络管理和拥塞控制机制将层出不穷。同时,开放标准与跨厂商联合促使底层互联技术更加多样化,Ultra Accelerator Link等开放标准将促进不同芯片和平台的高效协同。
总体而言,理解和优化AI集群网络结构对于提升人工智能研发效率、降低成本以及推动产业生态健康发展至关重要。网络作为连接计算资源的桥梁,是塑造智能计算能力核心竞争力的关键环节。通过深入学习Scale-Out Backend网络的高度可扩展设计、Scale-Up网络的高速GPU互联方案、前端网络的安全可靠访问、管理网络的稳定运维以及存储网络的高效数据传输,能够全面掌握AI集群构建的技术全貌,助力企业和研究团队打造面向未来的智能计算平台。 。