近年来,人工智能领域经历了快速的发展,尤其是大型语言模型(LLMs)在自然语言处理和推理任务中的表现不断刷新学术与工业界的认知。然而,要让这些模型具备真正的推理能力,面对复杂问题时产生符合逻辑且高效的解答,依然是AI研究中的核心挑战。DeepSeek-R1,作为一种通过强化学习(Reinforcement Learning, RL)驱动推理能力提升的代表性模型,正是在这一背景下应运而生,其突破性的训练框架为提升LLMs的智能水平带来了新契机。推理能力贯穿于智能体对信息的分析、判断以及综合推演等各环节,是人类认知的基石。传统的预训练语言模型通过海量语言数据学习模式,但其内在逻辑推理表现有限,尤其在面对多步骤、复杂计算或程序设计任务时表现尚不理想。与此同时,链式推理(Chain-of-Thought, CoT)提示方法的兴起,使得模型可以通过生成中间推理步骤来提升任务完成效果,但这类方法严重依赖人工标注的推理示范,拓展性和创新空间受限。
因此,如何摆脱对人类示范的依赖,赋予模型自主演进推理策略的能力,成为科研重心。DeepSeek-R1提出了一种全新的思路,即通过纯粹的强化学习过程激励模型自发发展出复杂而多样的推理模式,避免人为限制推理过程。其前身DeepSeek-R1-Zero利用Group Relative Policy Optimization(GRPO)算法,以最终答案的正确性为唯一奖励标准,对预训练模型进行大规模RL训练,不设定具体推理形式的约束,让模型通过不断试错,自主探索更优的推理路径。训练过程中,DeepSeek-R1-Zero表现出显著的思考时间增长,自动生成更长的链式推理文本,不断反思和验证结果,甚至尝试不同的解题策略。这种"自我进化"特性突破了传统依赖人类示范的局限,引入了"aha时刻",即模型推理质量和方法在某一点实现质的飞跃。DeepSeek-R1在继承此基础之上,针对语言混杂和表达流畅性问题设计了多阶段训练流程。
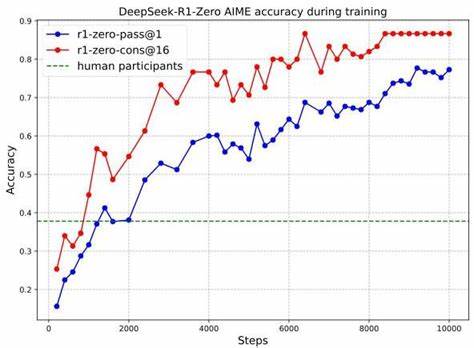
在首阶段,收集了大量呈现人类对话风格的"冷启动"数据,进一步优化思维流程的对话连贯性和语言一致性,解决了语言掺杂的困扰。后续通过拒绝采样和有监督微调(SFT)相结合,让模型不仅在推理能力上更为强劲,也提升了对通用任务的适应力。最终阶段融入了对有益性和安全性的强化训练,平衡推理能力和用户交互体验。该多阶段训练方案充分发挥了强化学习的激励机制,在提升推理能力的同时有效减少了模型输出中的歧义与错误。DeepSeek-R1在多个顶级推理与综合评测基准上均展现卓越表现,其中AIME 2024数学竞赛测试中,通过自一致推理法(Self-Consistency Decoding)实现超过86%的准确率,远超人类平均水平。此成果不仅体现在数学领域,也包括编程竞赛和高等生物、物理、化学领域等复杂问题,体现了其跨学科的广泛适用性。
此外,通过蒸馏技术,团队发布了多款体积更小但依旧具备强大推理能力的模型版本,为业界和学术界提供了宝贵资源,推动小规模模型在推理领域的进步。DeepSeek-R1的成功彰显了强化学习在语言模型推理领域的潜力,尤其是其无需繁复人工干预即可催生新的思维模式的能力。相比传统监督式学习,强化学习架构允许模型根据任务反馈不断调整策略,自主挖掘更有效的解题方法。这种探索优势极大地促进了模型多元推理能力的涌现,包括自我反省、结果验证以及动态策略切换,为设计未来自主智能系统开启新方向。然而,DeepSeek-R1也存在一定的局限。模型当前的结构化输出能力还有提升空间,尚未集成使用外部工具(例如搜索引擎、计算器)辅助推理机制,对部分软件工程任务的适应性有限。
此外,语言混合问题仍需改善,尤其是面对多语种查询时会出现中英夹杂现象。强化学习本身依赖可靠奖励信号,而构建通用且准确的奖励模型仍具挑战,防止奖励模型被策略"破解"同样是未来复杂任务应用时需要解决的问题。基于此,团队建议继续探索更健壮的奖励设计和工具整合机制。Ethics方面,随着推理能力提升,模型有被滥用的风险。例如更强的推理能力可能被用于生成具操作性的敏感内容,公开模型也易受到未授权的有害改造。DeepSeek-R1团队对安全性评估十分重视,通过多语言、多场景的安全测试,以及结合风险控制系统,努力保障模型的正当使用。
展望未来,推动语言模型推理能力的自主演进,将可能颠覆传统人工智能开发模式,实现更多无需人工示范的智能突破。DeepSeek-R1的研究表明,只要有清晰的目标评价机制和充足的计算资源,模型就能通过反复试探不断完善推理策略,并催生出适合多样复杂任务的创新思维。这将为教育辅导、科研辅助、自动编程乃至各类专业领域的智能化工具带来质的飞跃。同时,深入解决奖励信号设定、工具集成以及多语言支持等问题,则是下一步发展的关键。总结而言,DeepSeek-R1利用强化学习激励大型语言模型发展推理能力,开创了无需大量人工标注示范,通过纯粹自我优化实现复杂认知任务突破的新范式。其显著领先的数学和编程竞赛成绩,显示了强化学习在语言模型进化中的巨大潜力。
未来,结合更加丰富的任务奖励、结构化输出和工具辅助,DeepSeek-R1代表的思路有望引领智能系统进入更加自适应、自觉和高效的新阶段,成为推动人工智能迈向真正理解与创新的重要里程碑。 。