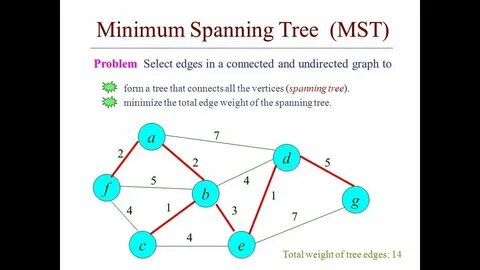
在数据科学和统计学中,最小生成树(Minimum Spanning Tree,MST)是一种重要的图论概念,广泛应用于网络设计、数据聚类和图像处理等领域。最小生成树是连通图的一个子图,包含所有顶点且边的总权重最小。本文将重点探讨最小生成树在跨相关性分析中的应用,特别是结合Figure 5的研究结果,帮助读者更好地理解这一技术的实际应用场景。 首先,了解最小生成树的基本原则是至关重要的。MST可以通过几种算法构建,其中最流行的两种是克鲁斯克尔(Kruskal)算法和普里姆(Prim)算法。克鲁斯克尔算法通过逐步添加边来最小化权重,确保没有形成环,而普里姆算法则从一个初始顶点开始,通过不断扩展到最小边选择邻接的顶点,逐步构建最小生成树。
在跨相关性分析中,最小生成树特别有用,因为它能够有效地展示变量之间的关系。当我们分析多个变量时,它们之间的相关性可以呈现复杂的网络结构。在这种情况下,最小生成树为我们提供了一种简明的方式来可视化这些变量之间的关系,突出显示出最重要的连接和潜在的聚类。 例如,假设我们正在研究一组金融资产的收益率,并希望了解它们之间的相关性。通过计算这些资产之间的相关性矩阵,我们可以得到一个权重图,其中每条边的权重表示两个资产之间的相关性程度。接下来,通过构建最小生成树,我们能够突显出那些最显著的资产之间的关系,帮助我们识别出在投资组合构建中最有潜力的资产组合。
在Figure 5中,我们可以看到特定数据集的最小生成树示例。此图展示了不同变量之间的跨相关性,反映了其相互之间的影响程度。通过可视化这种关系,我们不仅能够识别出特定变量的强烈关系,还能够发现潜在的聚类,这对数据分析师的后续决策过程至关重要。 最小生成树的一个重要优点是其直观性。与其他复杂的数据可视化方法相比,MST能够以简单明了的方式展现复杂的关系。这种可视化不仅可以帮助分析师在分析阶段识别模式,还可以在向非专业受众展示数据时提高理解力和可操作性。
因此,MST在商业智能和数据报告中越来越受到重视。 在跨相关性分析中,随着样本大小的增加和变量数量的增加,传统的相关性矩阵可能会变得难以解析。在这种情况下,最小生成树简化了信息的呈现,使得受众能够集中注意重要的变量关系。通过分析最小生成树,数据分析师能够做出更明智的决策,识别出潜在的风险和机遇。 除了金融领域外,最小生成树同样在其他科学领域展现了其强大的应用潜力。例如,在生物信息学中,研究者可以利用MST分析基因表达数据,揭示基因之间的关系和功能。
在社会网络分析中,最小生成树帮助研究者理解社交网络的结构和信息传播的路径。 然而,尽管最小生成树带来了很多好处,分析者在使用此技术时仍需注意其局限性。例如,MST只考虑了边的最小权重,而没有注重具体的权重值,这可能会导致某些重要信息的丢失。因此,在进行数据分析时,结合其他数据可视化技术和分析方法,以获得更加全面的见解,仍是非常必要的。 总结而言,最小生成树作为一种强大的数据分析工具,其在跨相关性分析中的应用为研究人员和数据分析师提供了直观且有效的可视化方法。在理解复杂的变量关系、发现数据中的潜在模式和提高报告的可读性方面,MST具有不可或缺的作用。
针对Figure 5中的研究结果,进一步探索和应用最小生成树的算法,将使数据科学的实践更加成熟,支持企业和研究机构做出更准确的决策。









