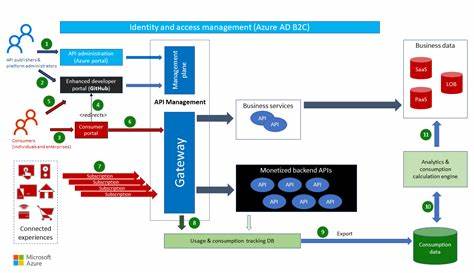
近年来,计算领域发生了深刻的变革,尤其是在人工智能(AI)应用的推动下,传统意义上的计算与网络边界逐渐模糊,网络正以前所未有的方式与计算紧密结合,试图成为计算本身。随着Moore定律的放缓和AI模型规模的急剧扩展,单纯依赖处理器性能的提升已经难以满足高强度计算和内存带宽的需求,网络作为数据互联的中枢,其角色和价值被重新定义。计算与网络的融合成为数据中心新时代的重要趋势之一,引领着计算架构的创新升级。网络不再是简单的连接设备,而是成为了承载计算负载,优化数据流动和存储访问的关键力量,这其中以GPU加速服务器和大规模AI训练系统的网络设计为代表。以NVIDIA的NVLink和NVLink Switch为例,这种高带宽、低延迟的内存共享网络架构,在GPU内部及节点间为海量AI训练提供了高效的数据传输通道。这种规模放大的网络不仅连接设备,更是GPU记忆体共享和协同计算的基础,极大提升了训练速度和效率。
由于AI模型参数规模的爆炸性增长,单个设备的计算和存储能力已难以支撑整体需求,网络作为扩展存储和计算资源的桥梁,在形成更大尺寸的内存域中发挥着不可替代的作用。伴随着专家模型和混合模型的普及,网络系统迫切需要更快、更宽、更灵活的连接能力来保证训练和推理过程中的数据高效流通。除了GPU内部的互联技术,芯片间的Die-to-Die(芯片片内)以及Chip-to-Chip(芯间)高速通讯技术同样成为了AI计算成本的重要组成部分。NVIDIA和AMD等厂商在此大力投入研发,打造如NVLink、Infinity Fabric等互联协议,助力多芯片模块(MCM)和芯片组的高效协同工作,从硬件层面优化整体计算性能。这种内嵌于芯片设计和封装中的互联费用虽然隐性,但对整机成本影响巨大,是AI和高性能计算(HPC)“巨无霸”计算设备价格高昂的关键因素之一。软件层面上,为支撑复杂的硬件架构以及丰富的AI算法开发,厂商投入大量人力资源。
从NVIDIA的CUDA-X软件栈到企业级AI软件服务,软件与硬件的协同优化大幅提升了计算资源的利用率和用户体验。然而,随着软件许可费用和增值服务的引入,整体系统开支中除了硬件投资,软件部分也成为成本的重要组成。除了节点间和芯片内互联网络外,数据中心的规模化和分布式计算需求进一步推动了对更强大规模外网络的依赖。传统的以太网和InfiniBand为代表的高速互联方案,依旧是分布式AI训练和HPC集群连接的支柱,但日益增长的数据流量和计算需求,让这些网络面临严峻的带宽、延迟和成本挑战。同时,云计算和边缘计算环境中,东西向(East-West)和南北向(North-South)数据流网络架构的平衡与优化,成为保证系统整体稳定性和性能的关键。数据中心互联(DCI)领域,光纤网络技术不断进步,支撑全球范围内的多地域数据中心互通,助力云服务商实现低延迟、大容量的数据同步和灾备。
鉴于网络成本在整体数据中心预算中占比日益上升,尤其是AI系统占据服务器支出一半以上,如何高效控制网络投入成为业界关注焦点。根据市场调研数据显示,近五年来,数据中心交换机市场规模持续增长,InfiniBand网络因AI训练需求爆发式增长,带动相关硬件销售额大幅提升。预计随着Ultra Ethernet标准的普及,未来将推动传统InfiniBand网络架构的革新,为规模外和规模内网络带来更多竞争和技术优化空间。未来,数据中心网络深度整合计算的趋势将更加明显。数据处理单元(DPU)的兴起,是网络在计算领域角色变革的又一体现。DPUs在提供数据包处理、安全隔离以及多租户管理等方面担负重任,是实现云和AI系统安全、弹性与高效的关键技术,未来或同时部署于服务器节点与交换机内部,成为网络与计算交织的桥梁。
尽管早期SmartNIC的热潮未能持续爆发,但AI应用的特殊需求为下一代网络加速器设备带来新机遇。网络不仅是数据传输的管道,更演变成数据预处理、分片重组甚至初步推理的计算平台。硬件厂商围绕GPU内外互联打造创新方案,推动PCIe 7.0与即将到来的PCIe 8.0标准,进一步提升数据传输速率,减少瓶颈。市场巨头和“反叛联盟”如AMD等正积极布局,利用Infinity Fabric及自有互联技术回应NVLink与InfiniBand的挑战,试图通过技术竞争拉低整体成本,将网络成本控制在合理范围。当前和未来的网络已不再是传统意义的单一连接工具,而是成为计算系统不可分割的一部分。网络架构的进步直接决定了AI训练的规模和速度,也影响云计算的灵活性及数据中心的经济效益。
随着AI时代的深入发展,“网络即计算”的理念将持续推动硬件设计、软件开发及系统集成等多领域的协同创新,为打造更智能、更高效、更经济的数据中心基础设施奠定坚实基础。正如网络在数据中心中的份量日渐加重,理解其与计算融合发展的趋势,对于制订未来技术路线和资金投入决策具有重大指导意义。