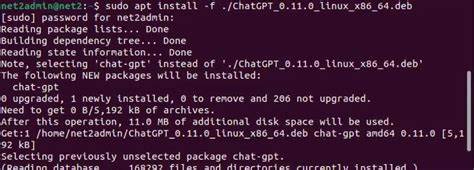
近日,全球广受欢迎的人工智能聊天助手ChatGPT经历了一次长达三小时的服务中断,这一罕见的故障事件引发了业界广泛关注。调研显示,此次宕机的根源来自操作系统Ubuntu 22.04的一次自动更新,更新涉及了关键的系统管理工具systemd。因该更新引发的复杂问题直接影响了ChatGPT的正常运行,导致大量用户在数小时内无法访问服务。Ubuntu作为一款企业及开发者广泛使用的Linux发行版,其稳定性和安全性向来被用户期待,但自动更新机制带来的潜在风险再一次提醒了运维团队自动化管理的双刃剑效应。Ubuntu 22.04版本发布已久,具备LTS(长期支持)承诺。该版本的系统更新机制默认启用了某些关键组件的自动更新,目的是保证系统安全漏洞及时修补,维持最新性能。
systemd作为Linux系统中管理启动与服务的核心组件,其更新尤为关键且敏感。然而,正是这一更新引发了连锁反应,扰乱了ChatGPT服务器环境中的多个服务依赖。具体表现为systemd的新版本在处理服务重启及依赖关系时出现了不兼容或配置冲突,导致ChatGPT所在的后端基础设施无法正常完成请求处理。由于ChatGPT的服务架构高度依赖实时计算和响应速度,任何底层系统的异常都可能放大全球用户体验的影响。此次停机暴露了系统自动更新策略与复杂云服务平台的冲突隐患,也凸显了运维自动化需配备更严密监控与回滚机制的必要性。事件发生后,OpenAI及相关云服务供应商迅速介入调查,联合Ubuntu社区技术人员定位问题核心,最终确认systemd更新在某些配置项上与现有环境不兼容。
紧急恢复工作启动后,通过手动降级和修复配置,部分服务器逐步恢复服务,最终在大约三小时内全面复苏。此次宕机不仅给无数依赖ChatGPT提高工作与学习效率的用户带来不便,也为业界敲响了技术基础设施韧性建设的警钟。针对类似问题,专家建议在自动更新前加入多层测试流程,尤其是关键系统组件更应谨慎推送。同时,加强分布式服务环境中的容错设计和快速故障切换机制,有助于最大限度减少单点更新带来的风险。此外,提升运维团队对自动化工具的掌握及应急响应能力,构建动态配置监测和智能报警系统,也是未来确保服务稳定不可或缺的环节。从用户角度出发,建立合理的预期管理体系和多渠道状态通报机制,有助于减轻服务中断带来的负面情绪,增强品牌信任度。
这一事件还促使云服务商与操作系统发行方加强沟通协作,共同制定安全、稳定的更新策略,力求更新与服务连续性的平衡。整体来看,ChatGPT因Ubuntu 22.04系统更新引发的三小时宕机是一次复杂技术体系内循环影响的真实写照。它揭示了在快速发展且高度复杂的人工智能与云计算环境下,传统操作系统及其更新策略如何需调整以适应现代应用需求的挑战。未来,随着AI服务的进一步普及与深化,对底层系统稳定性和自动化运维水平的要求必将更加严苛。这为相关行业带来了新的思考维度:如何在保障安全性的基础上实现灵活高效的系统维护与升级,并将潜在风险降到最低。对于广大技术人员、企业管理者及终端用户而言,关注此次事件背后的技术细节和管理策略,有助于汲取教训、优化流程、提升整体服务质量,进而推动人工智能服务的健康稳定发展。
最终,这场突发的ChatGPT宕机事件不仅是一段技术故障记录,更是新时代信息技术与服务模式融合过程中宝贵的实战经验,值得整个行业深刻反思与借鉴。