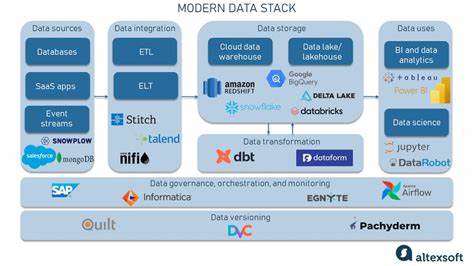
随着大数据时代的到来,企业在数据处理方面面临着前所未有的挑战。传统单机处理方式已无法满足海量、多样化数据的存储和分析需求,分布式数据处理技术因此成为推动数字化转型的核心动力。现代分布式数据处理技术栈涵盖了数据采集、存储、计算、调度和监控等多个层面,形成一个复杂且高效的生态系统。本文将深入探讨这些关键技术组件及其在实际场景中的应用,帮助读者全面理解当前最具竞争力的分布式数据处理方案。 大型数据应用首要关注的便是数据采集和实时流处理。随着物联网、移动互联网的快速发展,数据产生速度极快,只有通过高性能流处理框架,企业才能实现实时数据分析和响应。
Apache Kafka作为现代流处理的中坚力量,因其高吞吐量和可扩展性,广泛用于构建实时数据管道,保障数据高效稳定地从源端传输到下游系统。Kafka强大的持久化机制和分区设计,使得在海量数据环境下依旧能够保证顺序性和容错性。 在流数据的处理层面,Apache Flink和Apache Spark Streaming以其灵活的计算模型和丰富的API受到业界认可。Flink强调事件驱动和状态管理能力,适用于低延迟实时分析与复杂事件处理。Spark Streaming则凭借它的微批处理机制和与Spark生态的无缝集成,成为批流一体化的优秀选择。二者各有优势,企业可根据实际需求灵活选用,实现高性能数据流计算。
谈及数据存储,现代数据处理架构通常采用分布式文件系统和分布式数据库结合的方案,既满足大规模数据存储需求,又保障高并发访问性能。Hadoop分布式文件系统(HDFS)作为开源领先产品,为离线批处理提供了卓越的持久性和容错性支持。与此同时,列式存储和云原生数据仓库的兴起,如Apache Parquet格式和Amazon Redshift,进一步提升了查询效率和存储优化,使得大数据分析更为高效和经济。 数据仓库和数据湖的融合趋势日益明显。数据湖通过存储结构化和非结构化数据,为多样化分析提供基础,数据仓库则聚焦于业务指标与决策支持。现代平台如Databricks的Lakehouse架构,突破传统数据孤岛,将数据湖的灵活性与数据仓库的管理与性能相结合,实现单一真相和实时分析的统一目标。
这一创新架构极大地简化了数据治理流程,提高了数据的可用性和一致性,推动业务智能前行。 计算框架是分布式数据处理的核心所在。随着云计算的普及,弹性计算和资源调度成为关键。Kubernetes引领了容器编排的浪潮,为分布式计算提供了稳定的基础设施,使得各种数据处理任务能够灵活部署与自动伸缩。利用Kubernetes,数据处理作业可以更高效地利用底层资源,提高容错能力和运维效率,减轻了传统大数据平台带来的运维难题。 数据调度与工作流管理工具在复杂的数据生态系统中扮演着调解者的角色。
Apache Airflow因其灵活的DAG(有向无环图)定义和丰富的插件支持,成为业界主流的调度平台。它能够调度跨多种数据处理引擎和系统的任务,确保数据管道的自动化和稳定。同时,随着多云和混合云环境的普及,调度系统逐渐支持跨环境协同,实现数据工作的无缝衔接和灾备能力。 安全与数据治理是现代分布式数据处理不可忽视的方面。企业需要确保数据访问的合规性和隐私保护,结合细粒度权限控制、数据加密和审计机制。在这方面,Apache Ranger和Apache Atlas提供了完整的安全策略管理和元数据治理解决方案,通过统一管理确保数据资产的安全与合规,提高企业数据治理水平。
展望未来,人工智能与机器学习的深度融合将进一步推动分布式数据处理技术的发展。通过将机器学习模型部署在流处理引擎和实时计算框架中,企业不仅能够实现自动化的数据洞察,还能及时调整业务策略,抢占市场先机。随着边缘计算、5G和混合云迈入成熟阶段,分布式数据处理架构将向更加去中心化、低时延的方向演进,满足多样化的应用场景需求。 总的来说,现代分布式数据处理技术栈融合了多种先进技术与理念,构建起强大的数据生态系统。它涵盖了从数据采集、存储、计算到调度与治理的完整生命周期,确保企业能够高效管理并深挖数据价值。理解并运用这些技术,不仅能提升数据处理效能,而且能为企业数字化转型提供坚实的基础,助力在激烈的市场竞争中占据优势地位。
随着技术不断演进,分布式数据处理将持续革新,为未来的数据驱动决策开辟更广阔的道路。