随着数据技术的飞速发展,开发者和数据工程师们对高效、智能的数据管理工具的需求日益增长。Azure Databricks作为一个领先的大数据分析服务平台,因其强大的数据处理和机器学习能力,逐渐成为数据领域的重要利器。而GitHub Copilot,作为一款基于AI的智能代码辅助工具,也日益融入开发者的日常工作。将两者结合,通过Model Context Protocol(简称MCP)实现无缝沟通和数据操作,成为提升数据操作效率的新趋势。通过MCP协议,一款小巧的Python服务器能够在Visual Studio Code环境中运行,为GitHub Copilot注入全新能力,使其能够直接执行SQL查询,检测表结构,并进行表间差异比较。这样的集成不仅刷新了开发者们的工具使用体验,也大大简化了数据操作流程。
理解MCP如何激活Copilot执行复杂的数据任务,有助于拥抱自动化和智能化的数据开发新时代。GitHub Copilot通常以智能代码完成功能帮助程序员迅速编写代码,但其与数据平台的交互能力则受到局限。传统情况下,开发者必须频繁在代码编辑器与数据平台间切换,进行复制粘贴、脚本调整等繁琐操作,这不仅耗费宝贵时间,还增加了人为错误风险。而MCP的引入,则将这些环节高效整合。MCP作为一种协议框架,专门设计用于实现语言模型与外部工具的交互。通过MCP,语言模型如Copilot可以调用服务器提供的功能接口,获得精确的数据响应,从而实现复杂的数据交互和操作。
具体到Databricks场景,一个Python服务器被开发出来,部署在VS Code中,充当MCP服务端。该服务器能够利用环境变量或者MCP输入参数从Azure Databricks环境拉取配置信息,包括工作空间URL、HTTP路径、访问令牌、数据目录和模式等,确保对目标数据库的安全和准确访问。该服务具备三大核心能力。首先是SQL执行能力,用户可通过Copilot自动生成查询脚本,并由服务器直接将其传递至Databricks执行。这样,数据分析或变换步骤可以快速落地,无需离开编辑器手动操作。其次是表结构检测功能,服务器可以帮用户快速获取某张表的字段、数据类型等详细信息,极大地方便了后续数据处理和代码生成。
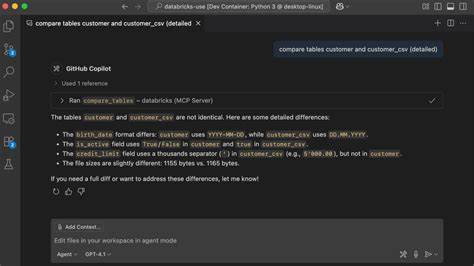
最后则是表间差异比较能力。传统比较表数据往往需要导出两张表,借助外部工具进行对比,过程繁琐且对大数据不友好。该服务器通过导出表头一定数量数据,利用经典的Unix diff算法,逐步增量比较样本数据,能快速返回简洁的统一差异,帮助Copilot理解决策,提升代码生成的准确性。整个集成让GitHub Copilot真正拥有了“智能数据代理”能力。用户只需在VS Code中打开配置文件填写相关参数,启动服务器,几乎无需额外操作即可享受包括查询执行、结构查阅与数据比对的强大功能。生命周期长效的交互循环,避免了频繁的上下文切换,带来极致的用户体验。
MCP配置文件中对于各参数均设置了友好提示,例如工作空间地址不含协议部分,HTTP路径指向具体仓库或集群,访问令牌要求具备SQL访问权限,数据目录和模式可自定义或采用默认值。确保初学者快速上手,既保障安全又兼顾灵活性。利用该工具,数据开发者可以在GitHub Copilot的辅助下,快速完成数据架构与数据变换的生成,将客户CSV文件平滑加载至目标表,同时通过表差异对比反馈结果细节,有效定位格式不匹配或数据质量隐患。整个流程由生成SQL脚本,到执行查询,再到差异检测,像一个紧密合作的智能代理帮助开发者驾驭数据飞轮,极大缩短传统ETL与数据验证的周期。技术实现层面,QueryTool会自动为没有限制条数的查询添加默认查询限制,避免大表造成性能瓶颈。TableCompareTool则以递增样本规模生成临时文件,迅速发现数据差异并限制输出,不仅提高了反馈效率,同时保障数据隐私,不必全量导出。
所有配置从环境或MCP输入读取,保证高度动态和灵活,开发者轻松适配不同Azure Databricks环境和场景。本项目开源并发布MIT许可证,社区可自由使用和扩展。正因如此,未来还可以添加更多数据操作工具,如作业执行与监控等,Copilot会自动发现并调用,构筑一个智能多功能数据操作代理生态。总体而言,将MCP与GitHub Copilot和Azure Databricks结合,开辟了AI辅助数据操作的新天地。既提升了开发效率,降低了人为错误,也大大优化了用户体验,让复杂数据处理变得轻松自然。针对企业级数据团队,这样的创新工具将帮助加速数字化转型,释放数据真正价值。
期待更多开发者与数据专家采纳并贡献,推动数据驱动未来的智慧工作。









