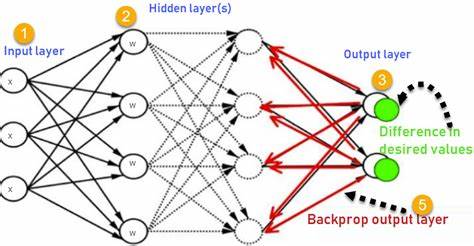
在人工智能领域,反向传播算法被广泛认为是神经网络训练的基石。它在深度学习崛起过程中扮演了不可或缺的角色。尽管反向传播本身的数学表达看似复杂,但其核心思想却极为直观。通过解析损失函数相对于模型参数的变化率,反向传播帮助我们找出调整权重和偏置的方向,从而最大限度地降低预测误差,提高模型性能。 神经网络本质上是由多层节点组成的复合函数,每层的输出作为下一层的输入。训练神经网络的目标是最小化损失函数,通常选用均方误差(Mean Squared Error)等衡量预测值与真实值偏差的指标。
反向传播利用链式法则计算损失相对于各参数的梯度,从输出层开始一路向输入层反向传播梯度信息,计算每个参数对整体误差的贡献。 简单来说,反向传播就是逐层计算损失对参数的偏导数,即梯度。前向传播用于计算预测输出和当前损失值,而反向传播则负责利用这些结果,结合链式法则,递归求导,进而指导参数调整方向。参数根据梯度方向进行更新,通常结合学习率这一超参数,采用梯度下降算法完成优化迭代,不断减少模型预测误差。 以单个神经元的线性模型为例,假设输入为x,权重为w,偏置为b,输出为y^,对应目标输出为y。损失计算为两者差值的平方。
通过微分链式法则,计算损失对权重和偏置的梯度。调整过程中,如果发现增大权重会提升损失,则反向传播会指引减少权重。相反,若降低权重能够减少误差,则梯度为负,权重增加,直到损失收敛到最小值。 在更复杂的非线性神经网络中,反向传播仍然适用。网络由多层非线性变换(例如激活函数ReLU)和众多参数构成,每一层的输出都依赖前一层结果。反向传播利用链式法则逐层传递误差信息,计算每个连接权重的梯度,从而支持深层神经网络的训练。
非线性激活函数使模型具备了表达复杂函数的能力,反向传播则确保参数更新有效,保证优化过程稳定进行。 实际训练中,反向传播与梯度下降紧密结合,通过小批量数据(Mini-batch)重复前向传播和反向传播,逐步调整网络参数,减小训练误差。参数调优过程中,学习率的选择直接影响训练速度和最终模型效果。过大会导致训练不稳定,过小则可能陷入局部最小值。为此,常结合动量法、自适应学习率优化算法(如Adam)等技术提升训练效率。 反向传播还受到自动微分技术的支持。
计算图以节点形式表达网络运算,自动微分通过正向传播计算中间变量,同时利用反向传播高效求梯度,极大简化了复杂网络的训练过程。现代深度学习框架如TensorFlow和PyTorch正是基于这一机制实现灵活高效的神经网络搭建与训练。 理解反向传播的核心机制,有助于理清深度学习模型本质,发现训练过程中的潜在问题,如梯度消失和梯度爆炸。通过设计合理的网络结构、选择合适的激活函数以及初始化方法,可以缓解这些问题,保证反向传播发挥作用,使网络有效学习。 反向传播不仅是训练人工神经网络的标准方法,也奠定了深度学习广泛应用的基础。从图像识别、自然语言处理到语音合成等领域,无不依赖该算法优化参数以提升模型表现。
通过不断的研究和改进,反向传播算法也在适应更大规模、更复杂结构的神经网络,实现更丰富的人工智能任务。 总结来说,反向传播是一种利用微积分中的链式法则计算梯度,并结合梯度下降不断优化神经网络参数的过程。它使得模型能够沿着误差最速下降方向调整权重和偏置,最终降低预测误差,提高泛化能力。对其深入理解,为算法调优和模型创新提供了坚实基础,也是掌握现代深度学习不可或缺的一环。 未来,随着神经网络结构日益复杂且应用领域不断扩展,反向传播仍将是核心技术之一。结合新的优化方法和自动化工具,反向传播的效率和效果将持续提升,推动人工智能技术迈向更高峰。
深入掌握反向传播,将助力研究者和工程师更好驾驭神经网络,创造更具智能化的解决方案。