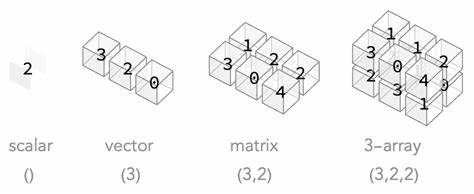
在当今数据科学和机器学习的蓬勃发展背景下,数组作为存储和处理数据的核心结构,承担着不可替代的重要角色。传统的数组编程语言往往面临着类型表达能力不足和安全性保障有限的问题,这使得开发者在处理复杂数据结构时容易出现索引错误和难以维护的代码。针对这一挑战,代数形状(Algebraic Shapes)作为一种新兴的类型系统理念,正在引领数组结构化的技术革命,赋能编程语言以更强的表达力和类型安全性,推动高效且可靠的数组编程实践。 静态类型系统一直被视为提升代码质量和性能优化的利器,它通过类型信息在编译期捕获潜在错误,减少运行时异常。而数组语言的类型系统传统上处于两种极端:一方面,大多数数组语言仅以元素类型或维度数量简单区分数组类型,缺乏对数组形状的细致表达;另一方面,部分语言借助依赖类型实现强类型约束,但这种形式的类型系统往往复杂且难以拓展,甚至面临不确定性和不可判定性。因此,在实际数据科学和机器学习领域,动态类型依然被广泛采用,保障了使用便利性但降低了类型安全。
针对这一行业痛点,研究者提出了一种名为Star的新型数组编程范式,其核心创新在于引入了代数形状的概念,利用结构记录(structural records)和变体类型(variant types)结合子类型机制,对数组的索引和形状展开精细刻画。通过丰富的类型表达,Star系统不仅防止了常见的索引越界等安全错误,也为开发者提供了显式描述数组结构的能力,大大增强了代码的可维护性和可读性。 Star语言的设计理念核心在于“结构即类型”,通过将数组索引映射为带有名称和约束的结构类型,而非简单的数值范围表达,类型系统能够精准识别合法的索引访问行为。这种基于代数子类型的设计避免了传统方法中对复杂算术表达式求解的困境,转而利用子类型多态实现灵活的类型推断和安全保障。此外,虽然当前Star实现聚焦于子类型多态,但其支持代数子类型的潜力预示了未来结合ML风格多态的高效类型推理机制,为数组编程的表达性与灵活性打开了新的维度。 代数形状的应用不仅限于索引安全,它还极大地促进了多维数组的结构说明和操作。
借助结构性记录,程序员可以为数组的每一维赋予语义名称,类似标签化的坐标系统,有效避免因维度混淆带来的逻辑错误。同时,变体类型赋予数组灵活的拓扑结构形态,满足复杂数据场景如异构集合或联合数据类型的建模需求。这样的设计对现代机器学习中的张量操作尤为契合,使得算法实现更具语义感和稳健性。 在数据科学生态系统中,诸如NumPy、xarray等库逐渐支持带标签的多维数组操作,反映了业界对结构化数组表达的关注。Star及其代数形状方法为此类趋势提供了理论和实践上的坚实基础,使得类型系统不仅能检查索引安全,也能表达复杂形状约束和数据之间的关系。此外,相关研究指出,结合路径依赖类型和结构子类型,可以进一步实现更强的多态特性和类型安全,这为Scala等语言的未来发展提供参考借鉴。
代数形状技术同样回应了高性能计算与自动微分的需求。在自动微分和并行计算中,对数组索引和形状的准确描述尤为关键,避免数据错配和计算错误带来的性能和准确性损失。通过静态类型保证,Star等新型语言框架能够在编译阶段阻止这些问题,提升运行时效率和代码健壮性,推动科学计算和深度学习框架性能迈上新台阶。 进一步探讨,代数形状的类型系统基于布尔代数和集合论思想,使类型之间的子类型关系和多态推断变得更为直观和易于实现。相关技术如MLsub和MLstruct展示了如何在实用语言中集成复杂子类型与多态特性,并保持类型推断的可行性和效率。这为现代函数式编程语言引入代数形状理念提供了理论支撑,并促进数组编程从经验驱动向类型驱动转变。
然而,代数形状的广泛应用也面临挑战。其类型系统的设计与实现需要在表达能力、类型推断复杂度及编译性能之间取得平衡。如何设计易用且强大的代数子类型语言,确保类型系统的判定性和推断的自动化水平,是未来研究的重要方向。同时,生态系统支持、与现有数组库和编程语言的集成兼容,亦是推动技术普及的关键因素。 总之,代数形状作为一种创新的数组类型结构化方法,极大地拓展了静态类型系统在数组编程中的应用边界。它通过结构化的类型表达提升了数组操作的安全性、表达力和维护性,为数据科学、机器学习等领域的大规模数据处理任务提供了强有力的编程工具和理论支撑。
随着相关研究和实践的深入,代数形状有望成为未来主流数组编程语言的重要组成部分,引领开发者迈向更高效、更安全、更智能的编程新时代。