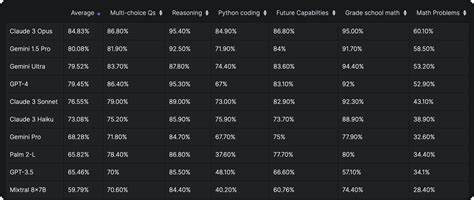
随着人工智能技术的不断进步,大型语言模型(LLM)在数据科学领域的应用日益广泛。为了更有效地评估这些模型在处理复杂数据科学任务中的能力,业界引入了新一代数据科学LLM基准测试。这一基准测试不仅为研究者和开发者提供了客观衡量模型性能的标准,也促进了模型优化和创新。新数据科学LLM基准测试的诞生,标志着数据科学与自然语言处理技术之间的深度融合,推动了跨领域智能工具的发展。了解这一基准测试的背景意义,有助于更好地把握当前AI技术的演变方向,并为行业应用提供指导。基准测试的设计充分考虑了数据科学中的核心任务,包括数据预处理、特征工程、统计推断、机器学习模型构建、结果解释与可视化等。
在评估过程中,模型不仅需要理解复杂的数学和统计概念,还需具备解决实际问题的能力。这种综合性的考核,能够全面反映模型在真实世界数据科学任务中的表现。此外,新基准测试对模型的对话能力、上下文理解以及多模态信息处理等方面也提出了更高要求,体现了现代数据科学工作环境的多样性和复杂性。基准测试的推出,为业界树立了统一的性能衡量标准,促进了不同团队和机构间的技术交流与协作。通过公开透明的数据和评测结果,推动了模型创新和性能优化,助力构建更加强大和高效的智能数据科学工具。同时,这也为数据科学从业者提供了选择与评估模型的科学依据,提高了实际应用的可靠性和效果。
值得注意的是,新数据科学LLM基准测试还关注模型的公平性和可解释性,呼应了当前人工智能伦理的热点议题。通过引入多样化的数据集和任务类型,测试模型在不同场景下的表现,减少偏差和不公平现象,增强模型的可信度。未来,随着数据量和复杂度的持续增长,基准测试将不断升级,更好地适应技术发展趋势和业务需求。与此同时,研究者们也在探索将基准测试结果与自动化模型更新和调优机制相结合,实现智能模型的持续优化和性能提升。总结来看,新数据科学大型语言模型基准测试不仅是技术评价的工具,更是推动人工智能技术与数据科学深度融合的催化剂。它引领着行业迈向更智能、更高效、更可信的未来,拓展了人工智能在数据分析、机器学习和决策支持中的应用边界。
为实现这一愿景,学术界、产业界与政策制定者需携手合作,共同推动基准测试体系的完善与创新,促进可持续发展的人工智能生态建设。 。