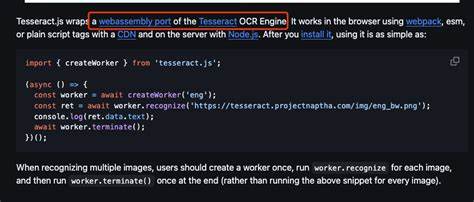
随着人工智能技术的飞速发展,光学字符识别(OCR)正逐渐成为数字化办公、自动化数据录入以及文本分析中的关键技术。Tesseract OCR作为开源OCR引擎的佼佼者,被广泛应用于各种图像文字提取场景。Rust语言因其安全、高性能和优秀的并发能力,成为构建稳定高效OCR服务的理想选择。本文将详细介绍如何在Rust环境下创建并使用Tesseract OCR,尤其适合处理发票和收据等复杂文本布局的图片。 首先,需要明确的是,Rust中的Tesseract OCR并非直接调用官方C++库,而是通过rusty_tesseract这一封装库实现。这个第三方库提供了方便的接口,底层调用Tesseract进行识别,并且与Rust的生态无缝结合。
准备工作包括确保你的系统中已经安装了Tesseract OCR引擎及对应的开发库,如Ubuntu系统的libtesseract-dev包。此外,安装语言包以匹配你需要识别的文本语言,如阿拉伯语的ara或者英语的eng是非常必要的。 项目搭建也十分简单。在Rust环境中,利用cargo工具创建新项目,然后在Cargo.toml文件中添加actix-web、rusty-tesseract、image、serde以及相关依赖,为后续开发做好准备。actix-web框架提供异步HTTP服务器支持,能够高效处理多用户上传请求。image库用于图像解码和预处理,而serde用于JSON序列化,方便将OCR结果以结构化数据形式返回。
核心代码部分主要是实现OCR的HTTP POST接口,用户通过multipart表单上传图片,服务器接收后进行解析。代码中首先会校验文件大小,防止空文件提交导致错误。随后调用image库中的ImageReader打开并自动识别图片格式,解码成动态图像。在这之后,动态图像将被转换成rusty_tesseract可处理的Image类型,以适配Tesseract的接口。 配置OCR参数是关键环节。通过Args结构体,设定语言参数lang、分辨率dpi、页面分割模式psm以及OCR引擎模式oem。
这里应特别关注PSM类型,PSM 12适合发票这类稀疏文本结构,能够更准确地识别分散排列的文字区域。DPI设置为380保证扫描图像清晰,从而提升识别率。语言参数根据实际文档调整,确保识别引擎加载正确的训练数据。 调用rusty_tesseract的image_to_string函数即可实现图像到文本的转换。结果如果成功,将被封装进自定义的响应结构体中,以JSON格式返回给客户端。错误处理环节同样完善,当遇到OCR失败、图像解码异常或者格式不支持时,API会向调用者返回相应的错误码和提示信息,增强开发调试体验。
整个系统基于actix-web构建,启动时监听本机8080端口,暴露/ocr路径接口。通过curl或者Postman,开发者可以快速上传图片测试识别效果。该方案不仅灵活支持多语言环境,还能通过扩展增加图像预处理功能,如调整亮度、灰度处理等,进一步提升识别精准度。 选择Rust实现OCR API的优势不言而喻。Rust编译器保障零内存泄漏和高并发性能,结合Tesseract强大的文字识别能力,打造出的服务既高效又可靠。相比于Python等语言,Rust在多线程及资源管理方面更具优势,适合生产环境部署。
未来可扩展的方向包括将OCR结果与自然语言处理技术结合,自动提取发票中的关键信息如日期、金额、供应商名称等,实现智能化数据录入。结合数据库存储和搜索,引入前端界面打造完整的文档管理系统,将进一步提升应用价值和用户体验。此外,支持批量图像处理或视频帧文本识别也是值得探索的领域。 综上所述,利用Rust语言和rusty_tesseract库构建基于Tesseract OCR的文字识别服务,不仅实现了高效的图像文字提取功能,还具备良好的扩展性和稳定性。合理配置OCR参数,结合优质的图像输入,可以最大化识别效果,尤其适用于发票等复杂文本文件。希望本分享能够帮助开发者快速上手Rust OCR项目,利用现代技术打造智能、高性能的文档数字化解决方案。
。