在当今人工智能领域,模型的性能和推理速度是衡量其实用价值的关键指标。图像生成作为其中一个热门方向,尤其依赖于高效的硬件和优化方法。最近,Meta和Hugging Face的专家们发布了Flux Fast项目,该项目展示了如何在NVIDIA最新的Hopper架构GPU——H100上,使Flux模型实现近2.5倍的运行速度提升。通过结合PyTorch的深度优化技术与硬件特性,Flux Fast不仅刷新了开源模型的性能下限,还为研究者和开发者提供了实用且容易上手的优化方案。本文将带领读者剖析Flux Fast背后的技术细节、优化策略以及实践经验,帮助广大AI从业者把握前沿趋势,从而提升自家图像生成任务的效率和质量。 Flux作为当前最具竞争力的开源权重生成模型之一,凭借其在图像合成领域的出色表现,迅速赢得了广大开发者关注。
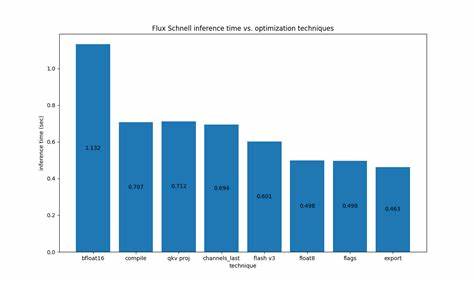
此前,团队曾推出diffusion-fast项目,以纯PyTorch代码优化Stable Diffusion XL管线,提升速度达3倍。Flux Fast项目则是在这一基础上,针对Flux.1-Schnell和Flux.1-Dev两个版本进行更加深入的性能挖掘,充分发挥H100芯片的强大计算能力,堪称动画渲染、视觉创作等对速度要求极高场景的理想选择。 实现这一目标,Flux Fast主要依靠的是PyTorch的torch.compile工具和多项底层硬件友好优化策略。torch.compile提供了“fullgraph=True”和“max-autotune”模式,使得模型的计算图能被充分捕获并通过CUDA Graphs实现内核调用的合并,极大降低了GPU调度时的开销,保证流水线的高效连续执行。此外,通过统一查询(query)、键(key)和值(value)投影矩阵,优化了注意力计算流程,在量化阶段提升计算密度,有效提高整体吞吐量。 对于数据布局,团队将解码器输出调整为torch.channels_last内存格式,该格式下的张量更利于并行计算和内存访问,配合NVIDIA最新的Flash Attention v3(FA3),进一步降低内存带宽压力。
同时,采用无缩放的float8格式(torch.float8_e4m3fn)进行输入转换以及基于torchao库的动态float8激活量化和权重量化,有效实现模型参数的压缩与加速,且精度损失极小。这种混合精度量化不仅减小了模型占用内存,也促进了计算速度的提升。 在编译器层面,Flux Fast团队针对PyTorch Inductor后端设置了多项调优参数。启用1x1卷积映射为矩阵乘运算(conv_1x1_as_mm),禁用了尾随融合(epilogue_fusion),以及通过坐标下降算法(coordinate_descent_tuning)全方位寻找最优内核配置,这些调整均旨在消除潜在性能瓶颈,保证Hopper架构GPU能以最高效率运行。特别是通过Ahead-of-Time Inductor编译(AOTI)结合CUDA Graphs,极大地缩短了模型启动延迟和内核调用次数。 值得关注的是,Diffusion模型与大规模语言模型(LLM)在计算性质上存在巨大差异。
Diffusion模型明显计算密集,关注点在于大量矩阵乘加运算的加速,因此Flux Fast在优化过程中避免简单复制LLM中的策略,而是深入挖掘符合图像生成特征的专项算法和技术。附加的优化如取消调度器中的CPU-GPU同步点(通过设置self.scheduler.set_begin_index(0))体现了对系统执行流细节的敏锐洞察,使得编译器流水线不被阻塞,达到更流畅的执行体验。 实践中,经过多轮逐步优化的Flux.1-Schnell在H100 700W GPU上实现了近2.5倍的速度增长。而Flux.1-Dev版本同样收获显著提升,并在图片质量上仅因FP8量化产生极其细微且难以察觉的变化。具体性能对比数据和视觉效果展示,充分证明了所用技术的稳定性和实用性,为开发者树立了可信赖的优化样本。 然而,Flux Fast团队也坦诚指出,目前主流的优化方案在复杂度和性能平衡间做出了妥协。
未来,融合定制的融合MLP和自适应LayerNorm内核依然是提升空间,等待社区的进一步探索。此外,鉴于Hopper架构GPU成本不菲,面向预算有限的消费者,Diffusers库中还提供了多种torch.compile兼容且更经济的优化方案,满足多样化需求。 综合来看,Flux Fast项目不只是一次性能提升的尝试,更是展示了如何以PyTorch生态为核心,结合最新硬件特性,实现开源模型跨越式加速的典范。它告诉我们,优化之路离不开对计算图、硬件架构及内核调度机制的深入理解,也强调了细节处微小改进带来的巨大回报。未来,随着技术逐渐成熟和工具链完善,更多AI模型将以此为标杆,开启高速且高质量的智能生成新时代。 对于开发者和研究者而言,Flux Fast提供了丰富的学习案例和工具支持,GitHub仓库含有所有细节代码;详细的文档和教程帮助入门与进阶;社区讨论渠道也随时解答疑问。
借助这样的资源,可以快速构建起高效的自定义生成流水线,充分发挥H100及后续GPU的潜力,加速创新迭代。 最后,Flux Fast鼓励广大从业者将其优化方法应用于其他模型,积极分享改进成果,共同推动开源深度学习生态向前发展。在机器学习高速发展的今天,如何高效利用硬件资源成为核心竞争力,Flux Fast正是一道启明灯,指引大家走向更加高效、绿色且智能的AI未来。