随着人工智能技术的飞速发展,大型语言模型(Large Language Models,简称LLMs)已成为自然语言处理领域的核心工具。这些模型凭借其强大的理解和生成能力,推动了无数应用的发展,包括机器翻译、文本生成、问答系统和对话机器人。然而,LLMs在实际部署中却面临着极高的计算和能源需求,尤其是在注意力机制这一区块。这一问题不仅限制了模型的扩展,也增加了环境负担。因此,如何在保证模型性能的同时大幅提升计算效率,成为研究热点。模拟内存计算(Analog In-Memory Computing,IMC)技术在这一背景下应运而生,为解决LLMs的能耗和延迟瓶颈提供了创新方案。
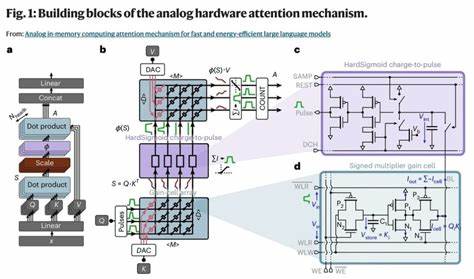
传统数字硬件如GPU在计算注意力机制时,反复读取存储于高速缓存中的键值(Key-Value,KV)投影,造成大量数据传输与存储能耗。KV缓存体积庞大且更新频繁,成为延迟和能耗的主要瓶颈。模拟内存计算通过将存储与计算功能集成于同一硬件单元,实现数据的本地并行处理,极大缩短了数据传输路径,降低了能耗。其核心优势在于利用物理设备的电学特性进行矩阵乘法等关键运算,取代传统数字运算方式。特别是基于增益存储单元的模拟存储器,兼具高速写入、高耐久性和多级存储能力,适合动态更新的KV缓存需求。增益单元利用存储电容的电压来表示权重,通过读出晶体管调节电流,实现输入信号与权重的乘积。
这种存储-计算融合架构支持高密度集成和三维堆叠,进一步提升存储效率。模拟计算电路则采用电荷到脉冲的转换方式,将累积的模拟电流转化为脉宽调制信号,避免了传统模数转换器带来的高功耗和面积开销。通过硬Sigmoid等非线性激活函数的模拟实现,保持了注意力机制的有效性与精度。为克服模拟硬件固有的非理想性,研究者引入了硬件感知的模型映射和训练策略。通过先将预训练的GPT-2等语言模型转换为数值上兼容的中间模型,再结合硬件特性进行适应性调整和微调,最终实现了硬件加速的注意力机制与软件原版模型相当的性能。该方式降低了重新训练整个模型的计算成本与时间。
模拟内存计算在注意力计算上的应用显著提升了速度和能效。相较于高端GPU加速卡,模拟IMC架构在注意力模型的推理阶段实现了百倍乃至千倍的能耗降低,延迟缩短至纳秒级别,极大促进了边缘设备和移动终端中的大型语言模型部署。与此同时,架构支持高并行度计算以及滑动窗口注意力机制,有效管理长序列输入,确保了模型的扩展性。该模拟内存计算方案兼顾存储密度与读写速度,通过精细的阵列分割和管脚设计解决了电阻压降导致的大规模阵列精度衰减问题,保证实际硬件实现的稳定性和准确性。未来,模拟IMC技术将继续受益于材料科学和半导体工艺的进步。基于氧化物半导体场效应管(OSFET)的增益单元能够实现更长的状态保持时间、更小的面积和多层堆叠集成,有望助推下一代能源高效且计算密集型人工智能硬件的发展。
此外,结合其他低功耗神经网络算子优化、算法硬件协同设计,模拟IMC方案的整体效能有望进一步提升。尽管模拟电路引入了部分非理想因素,例如存储电荷泄漏和非线性乘法,但通过硬件感知训练和体系结构设计,其对模型性能影响得到了有效限制。整体来看,模拟内存计算提供了一条破解大型语言模型高能耗与推理延迟难题的可行道路,标志着人工智能硬件迈入新纪元。随着AI模型规模的不断扩大,对算力和能效的需求亦呈指数级增长,提升计算硬件的能效成为可持续AI发展的关键。模拟内存计算注意力机制凭借其独特的存算融合优势,正逐步成为实现超高速、超低功耗生成式大模型的先锋技术。未来研究将继续聚焦于优化模拟电路设计、适配多样化神经网络结构以及提升系统的容错能力。
此外,加强模拟IMC与数字加速器的协同,实现混合计算体系的优势互补,已成为业界重点探索方向。总体上,模拟内存计算注意力机制不仅重塑了大型语言模型的硬件实现路径,也为构建绿色智能时代奠定了坚实基础。随着技术成熟与产业化进程加快,未来可期待更多基于模拟IMC的AI系统广泛应用于智能手机、物联网设备、自动驾驶和医疗诊断等领域,实现智能计算的普及与可持续发展。 。