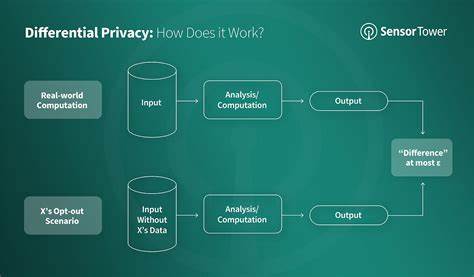
随着数据隐私成为全球关注的焦点,越来越多的企业与开发者开始应用差分隐私这一概念来保护用户的敏感信息。差分隐私是一种保证算法输出数据不会泄露个体信息的技术。然而,虽然它在理论上能提供强大的隐私保护,但在实际应用中却可能引发新的技术与开发挑战。本文将深入探讨差分隐私的基本概念、在人工智能中的应用、所带来的挑战,以及开发者如何应对这些问题。 差分隐私的基本概念 差分隐私旨在通过添加噪声来掩盖数据集中的个体信息,从而保护用户隐私。例如,开发者在执行统计分析时,通过在结果中添加随机噪声,使得数据输出不会精确反映任何单一用户的信息。
这样,即使数据被泄露,攻击者也无法通过数据反推个体的私人信息。这种技术被广泛应用于医疗、金融等领域,以提高数据处理的安全性。 在人工智能中的应用 在人工智能领域,尤其是机器学习模型训练过程中,大量的个人数据被用来进行算法优化和模型训练。传统的数据处理方式往往忽略了用户隐私的保护。然而,运用差分隐私的机器学习模型能够在不泄露个人信息的情况下,从全局数据中学习,并产生有效的预测结果。例如,苹果公司和谷歌等科技巨头已经在其产品中实现了差分隐私,确保用户数据的安全性。
尽管差分隐私在保护用户隐私方面展现了许多优势,但它的实施却并非易事。开发人员需要面对多种挑战,包括计算效率降低、准确性的问题以及系统的复杂性提高。 技术挑战 首先,差分隐私的实现往往需要复杂的算法设计和大量的计算资源。开发者在设计差分隐私机制时,必须在隐私保护水平和数据利用效率之间做出平衡。例如,添加过多的噪声虽然能提高隐私保护,但却可能降低数据的准确性,影响模型的性能。在实际应用中,如何找到这个平衡点,始终是开发者需要面对的重大挑战。
其次,差分隐私在大规模数据处理时容易引发效率问题。随着数据量的增长,所需的噪声处理和计算时间也随之增加,导致系统响应时间延迟,影响用户体验。在需要快速响应的应用场景中,差分隐私可能成为开发者的“绊脚石”。 准确性与隐私之间的矛盾 差分隐私的一个核心目标是避免泄露用户的个人信息,但在保护隐私的同时,难免会牺牲数据的准确性。在某些情况下,开发者为了实现高水平的隐私保护,不得不接受模型性能下降的现实。比如,某些应用场景需要极其准确的数据预测,而过多的噪声将导致预测结果的偏差,从而影响决策的有效性。
此外,差分隐私的实施往往需要不断的调整与测试,以确保实际效果达到预期标准。这种不断反复的过程,不仅耗费时间,还可能增加开发成本。这无疑给开发者增加了负担。 系统复杂性提升 引入差分隐私后,系统的整体架构也变得更加复杂。开发者需要同时考虑如何设计和实现隐私保护机制,以及如何确保模型的准确性和有效性。这种复杂性不仅会影响开发周期,还可能导致潜在的安全隐患。
例如,错误的噪声添加或不当的配置可能导致数据泄露的风险,反而危害用户隐私。 应对策略 面对这些挑战,开发者可以采取若干策略来降低风险并提高效率。首先,合理选择差分隐私算法和技术,在满足隐私保护要求的同时,尽量减少对模型准确性的影响。其次,加强与其他数据保护技术的结合,例如联邦学习,通过分散数据处理来保护用户隐私,同时仍然保持模型的有效性。 此外,开发团队应当建立严格的测试和监控机制,及时发现并解决潜在的问题,确保差分隐私实施的有效性。同时,教育团队成员理解差分隐私的重要性与限制,提升整体技术水平,防止因误操作导致的隐私风险。
总结 虽然差分隐私在保护用户隐私方面提供了一种有效的解决方案,但其在开发中的实施却带来了许多新的挑战。开发者需要在技术复杂性、准确性和隐私保护之间找到平衡,并运用合理的策略来应对这些挑战。只有这样,差分隐私才能真正发挥其应有的价值,推动人工智能领域的健康发展。在未来,随着技术的不断进步,差分隐私有望与更多创新技术结合,形成更稳健的数据保护方案。