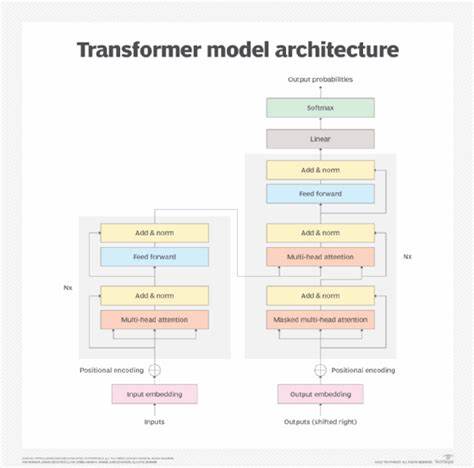
近年来,Transformer架构迅速发展并成为自然语言处理、计算机视觉等领域的主流模型,其出色的性能和强大的泛化能力引起了广泛关注。然而,深入研究Transformer的计算特性及其与计算机体系结构,尤其是内存层次结构之间的匹配关系,揭示了这些模型为何能够高效运行且具备扩展性。Transformer可以说几乎是“对抗性”地设计得与计算机内存层次结构相适应,这种适配性为计算资源的利用效率和模型性能的提升提供了坚实基础。理解Transformer与内存层次结构的互动关系,对于设计更高效的硬件加速方案、优化模型计算流程以及推动未来人工智能架构的突破意义重大。计算机内存层次结构是为了在不同的访问延迟和存储容量之间取得平衡而设计的。它通常包括高速缓存(L1、L2、L3缓存)、主存(RAM)以及更大而速度更慢的二级存储设备。
对于计算密集型任务而言,数据在内存和处理器之间的传输延迟往往成为性能瓶颈。Transformer架构的核心部分是自注意力机制,其计算特点依赖于大量的矩阵乘法和数据并行运算。令人惊讶的是,Transformer中的计算模式在许多方面与内存层次结构天然契合。首先,Transformer的输入序列通过嵌入矩阵转换成多维向量表示,这种紧凑的数据表示有助于充分利用高速缓存。输入嵌入和权重矩阵通常被加载到缓存中,减少了频繁访问主存的需求,从而降低了延迟。其次,自注意力机制的计算步骤中,大量的矩阵乘法和加权求和操作可以划分为子任务,这些子任务的小规模矩阵操作特别适合在缓存中进行,使得数据访问局部性保持较高水平。
相比传统循环神经网络,Transformer利用并行计算减少依赖链,降低了在时间维度上的连续访问,进一步提升了缓存命中率。针对多层堆叠的Transformer模型,层与层之间的数据传递也呈现良好的内存局部性。每层的中间激活结果可以局部缓存并快速供下一层计算使用,而无需频繁访问主存。另外,在训练过程中,反向传播所需的梯度计算和参数更新同样利用了类似的计算和访问模式,使得整体训练流程在内存层次结构中的表现更加协调。值得注意的是,Transformer的大规模模型参数通常无法完全放入高速缓存,这促使研究者和工程师关注如何通过分批处理、混合精度计算以及模型剪枝等技术减少内存占用与带宽压力。同时,创新的硬件设计如张量处理器(TPU)和图形处理单元(GPU)也针对Transformer特性进行了优化,在高速缓存设计和数据传输路径上实现了更高效的支持。
Transformer与计算机内存层次结构的适配性不仅体现在训练阶段,在推理阶段同样展现出优势。高效的缓存利用使得实时推理成为可能,即使输入序列长度较长,推理延迟仍能保持较低。这对于很多实际应用场景,如智能助理、机器翻译和语音识别等,都是至关重要的性能指标。此外,由于Transformer架构天然适合并行计算,在分布式训练环境中,内存层次结构的设计仍然发挥关键作用。分布式设备之间的数据交换需要优化通信带宽,而局部计算的内存高效管理则减少了跨节点的数据移动,实现了训练效率的最大化。在未来,随着模型规模的不断增大以及应用需求的多样化,Transformer与内存层次结构的协同优化将面临新的挑战。
如何进一步提升缓存利用率、降低存储访问延迟成为关键方向之一。结合硬件创新、算法改进和系统架构设计举行多角度协同攻关,有望带来人工智能计算效率的新突破。总的来说,Transformer架构与计算机内存层次结构的几乎“对抗性”设计,是其能够快速崛起为主流深度学习模型的重要原因。通过充分发挥内存分层的优势,Transformer实现了复杂计算任务的高效执行,为AI应用带来强大动力。在未来的人工智能发展道路上,深刻理解并继续优化这种适配关系,必将推动更大规模、更高效率的智能系统落地,从而在语言理解、图像生成、科学计算等多个领域创造更加辉煌的成绩。