近年来,随着深度学习技术的迅猛发展,Transformer架构在自然语言处理、计算机视觉等领域取得了革命性的进展。然而,传统的Transformer模型在扩展性和复杂推理能力方面仍面临诸多限制。基于能量的Transformer(Energy-Based Transformers, 简称EBTs)作为一种新兴的模型范式,凭借其独特的能量评估机制和优化架构,为机器学习带来了全新的视角和可能性。EBTs不仅实现了对多模态数据的有效处理,还在推理速度与性能提升方面展现出显著优势,标志着人工智能系统向着类人思考模式的方向迈进。 传统Transformer模型通过自注意力机制捕捉输入序列中信息的长距离依赖,但其在推理时常依赖单次前向传播,缺乏反复验证输入与输出之间关系的能力,类似于人类的“系统1”思维。而EBTs则引入了“系统2”思维的理念,强调推理过程中的反复优化与验证。
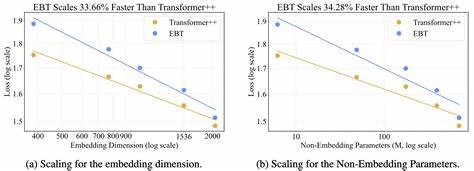
具体来说,EBTs训练一个能量函数,将输入和候选输出对映射为能量值。模型预测时通过梯度下降不断优化候选输出,使能量趋于最小,从而找到最匹配输入的输出结果。这种方法不仅提升了模型的推理能力,还提高了不同模态数据间的兼容性。 EBTs的优势首先体现在扩展速度上。研究发现,在训练过程中,EBTs在数据量、批量大小、参数数量、计算资源(FLOPs)和网络深度的增加下表现出更快的扩展率,相较于现有的增强型Transformer架构(Transformer++),最高提升达35%。这意味着在扩大模型规模和数据集时,EBTs能够更高效地利用资源,缩短训练周期,同时保证模型性能的稳步提升。
另外,EBTs在推理效率和效果方面展现出强劲实力。在语言任务中,EBTs通过系统2型的推理机制,提升了模型的理解和验证能力,比传统的Transformer++模型的推理性能提升高达29%。这种推理方式模拟了人类思考过程中的多次核验和修正,使得机器生成的答案更加准确可靠。除了文本领域,EBTs在视觉任务中也表现出色。以图像去噪为例,EBTs在保持或提升去噪效果的同时,显著减少了模型所需的前向传播次数,优于目前流行的扩散Transformer模型,展示了跨模态适应的潜力。 更为重要的是,EBTs在预训练阶段的表现可能与传统模型相当甚至稍逊,但在下游任务中的实际应用效果却明显优于其他模型。
这表明EBTs具备更强的泛化能力,能够通过其内在的能量优化机制,更好地适应多样化的任务需求和复杂场景。这种高泛化性对于构建通用人工智能系统至关重要,有望促进AI从特定领域专家向普适型智能体的转变。 能量基模型(Energy-Based Models, EBMs)的理论基础源于统计物理领域,其核心思想是用能量函数表示数据分布的特征,使模型可以直接优化能量来寻找最优解。EBTs融合了这一思想与Transformer高效的序列处理能力,将传统EBMs的优化优势与深度学习的表现力相结合,避免了对额外监督信号的强依赖,实现了真正的无监督学习能力。这不仅降低了注释数据的获取成本,也提升了模型的适用范围和鲁棒性。 从应用角度来看,EBTs有潜力推动多个重要领域的变革。
在自然语言处理方面,其强大的验证与推理能力使得复杂的语言理解、问答系统以及代码生成等任务更为高效和准确。在计算机视觉中,EBTs能够更好地处理连续和离散数据空间,提升图像修复、去噪、生成等任务的质量。同时,EBTs的跨模态统一框架,使得多模态学习和任务集成成为可能,促进异构数据的协同利用。 然而,EBTs的发展也面临挑战。能量函数的设计和优化过程需保证稳定性与收敛性,避免陷入次优解或计算资源浪费。此外,如何进一步提升模型的推理速度,减少梯度下降步骤以满足实时应用的需求,也是未来研究的重要方向。
同时,EBTs架构的可解释性尚需加强,以便开发者和用户更好地理解模型决策机制,增强信任度和安全性。 总的来说,基于能量的Transformer通过引入能量评估和优化机制,实现了模型的可扩展学习与类人思考能力,突破了传统Transformer架构的瓶颈。其在训练扩展性、推理性能、多模态泛化和无监督学习等多个方面表现出显著优势,奠定了未来人工智能发展新的里程碑。随着相关技术的不断完善和应用场景的开拓,EBTs有望引领下一代智能系统,促进人工智能从单一任务处理向复杂推理和自适应学习的全面跃升,打造更加智能、高效且多功能的未来人工智能平台。