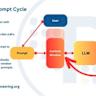
随着人工智能技术的发展,特别是大型语言模型(LLM)在自然语言处理领域的广泛应用,如何确保模型生成输出的结构化与准确性,成为推动技术落地的关键问题。传统的LLM输出往往不稳定,常见格式错误、内容缺失或者类型不匹配等问题,严重影响后续的数据利用和系统集成。在此背景下,Persuader作为一款以架构为核心驱动的TypeScript框架,突破了LLM输出的传统瓶颈,通过结合强大的验证逻辑和智能重试机制,实现了对语言模型生成结果的严格约束和稳定输出,成为业界关注的焦点。 Persuader核心创新在于采用了以Zod为基础的schema验证方案,将预期的数据结构和类型定义明确注入到调用流程中,使模型生成的文本不仅具备语义正确性,更能确保数据结构的严谨和类型的正确。框架在模型反馈环中接入了智能错误反馈和校正提示机制,当模型生成的结果未通过验证时,系统会自动将错误信息转化为具体且细化的纠正指导,重新向模型发出提示请求新的合规输出。此"验证驱动重试"不仅提升了结果质量,更有效减少了人为的出错率和后期数据清洗负担。
在实际应用中,Persuader能够处理各种复杂的场景。例如在用户信息抽取、客户反馈分析、文档内容结构化处理等任务中,框架能保证提取的姓名、邮箱、年龄、评分、评论内容等字段完全符合定义的规范,避免因模型表述多样性带来的格式混乱。同时,Persuader支持多种主流LLM厂商及接口适配,包括Claude CLI、OpenAI、Anthropic等,允许开发者无缝切换或组合不同的服务商,极大地增强了系统的灵活性和扩展性。 另一个重要特点是Persuader的会话管理能力。通过持久的上下文会话,框架有效利用之前交互形成的背景信息,实现上下文重用,节省了更多Token成本,降低了调用费用,也提高了整体的响应一致性。内置的预加载功能使得大规模文档或数据集能够分阶段传入模型,支持多步复合型任务的开展,而不会牺牲数据的完整性或准确度。
这对于处理长篇财务报告、法律合同、多文档分析等企业级应用尤其重要。 为了优化输出格式,Persuader引入了范例输出参数(exampleOutput),即通过提供具体且符合规范的样例示例,引导模型生成输出时遵循样例的结构和风格,大幅提升生成内容的统一性和规范度。这种方法有效解决了枚举值大小写不统一、数字范围不合适、数组元素数目波动较大等常见格式问题,从整体上稳定了业务数据交换的质量。 此外,Persuader框架设计时坚持严谨的开发理念,强调认知负荷管理和代码可维护性,模块划分细致,每个模块都限定在合理的代码行数范围内,便于开发者理解和维护。框架还配备了丰富的调试模式和日志系统,支持详细的运行监控和错误追踪,使得开发和运维人员能够快速定位问题,优化模型调用策略。配套的命令行工具提供了高效的批量处理能力和灵活的参数配置,满足从单次实验到生产环境大规模数据处理的多样需求。
从性能角度来看,Persuader自动利用校验失败反馈进行指数回退和渐进式增强尝试,这在保证高成功率的同时避免了盲目的重复调用,提升了整体效率。基于会话的交互还能显著降低重复上下文的Token消耗,据统计能够节约60%-80%的成本,在高频调用场景下带来显著经济效益。 面对复杂且多样化的业务需求,Persuader的"视角"系统(Lens)允许为同一份数据制定多重分析角度,如法律合规、商业价值、风险评估等,实现了对数据的多维度解读和结构稳定输出,为团队协作和决策支持提供了强有力的技术保障。 综上所述,Persuader不仅解决了LLM输出格式不稳定、类型不匹配等行业顽疾,更以其高度模块化设计和强大的适配兼容性,融入了智能重试、会话管理、范例引导、增强策略等先进理念,为构建稳定可信的智能数据提取和分析工作流提供了全方位的技术支撑。随着人工智能在企业数字化转型中的广泛渗透,Persuader凭借其技术优势和应用广度,必将在未来的数据智能生态中扮演举足轻重的角色。 。