随着人工智能技术的飞速发展,大型语言模型(LLMs)在许多自然语言处理任务中表现出色。然而,关于它们在事实性和结构化数据检索方面的能力依然存在明显不足。尤其是在处理复杂的多记录、多属性的表格数据时,模型的表现常常不尽如人意。RelationalFactQA是一项针对这一挑战精心设计的新型基准,旨在系统性地评估和推动大型语言模型在表格事实检索领域的能力提升。 RelationalFactQA的设计考虑了现有事实检索评测的不足。之前的基准往往聚焦于单一事实或简短答案的准确性,忽略了生成结构化、多条目知识的能力。
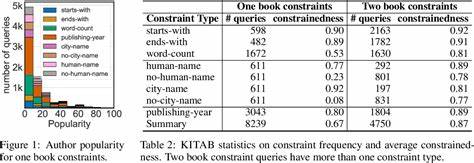
现实应用中,用户常常需要从数据库或表格中提取复杂的关系性信息,这对模型提出了更高要求。传统的点对点查询能力无法充分满足这种需求,模型面临的是如何从参数化知识中检索并以表格格式呈现多条相关事实。为应对这类挑战,RelationalFactQA引入了多样化的自然语言问题,配以精确的SQL查询和权威的标准答案表格,确保测试内容的全面性和严谨性。题目涵盖多种查询复杂度、不同的数据特征及多维度输出大小,使研究者能够细致分析模型在不同场景下的表现。 实验结果显示,尽管当前最先进的语言模型在单条事实检索方面已经取得显著进展,其在RelationalFactQA测试上的表现仍然不尽理想。准确率普遍未超过25%,且随着表格维度的增加,模型生成的事实准确性明显下降。
这一现象揭示当前技术在处理复杂关系事实、维持跨条目一致性及防止信息遗漏方面存在显著瓶颈。 此外,RelationalFactQA还暴露了大型语言模型在结构化输出格式控制、SQL语义理解与执行能力方面的不足。模型在解析自然语言问题与结构化查询语言之间的映射时,经常出现理解偏差,导致生成结果偏离真实数据库内容。表格格式输出的多维度特性增加了模型保持内在逻辑一致性的难度。 经过深入分析,研究团队指出,提升语言模型在表格事实检索上的能力,需要多方位改进。一方面,要增强模型的结构化推理能力,使其能够在多条记录、多字段查询中保持高准确率和完整性。
另一方面,优化模型对SQL语句的生成与执行理解,进一步辅以外部数据库接口,实现事实核实和动态检索,将极大提升结果的真实性和实用性。 RelationalFactQA的发布为学术界和工业界构建了一个宝贵的基准平台,促进对语言模型现实应用难题的深入探讨。它不仅推动模型在事实性和结构化数据处理上的技术突破,也为未来智能问答系统、大数据分析和知识图谱构建等领域提供了重要参考。 随着自然语言处理领域不断演进,RelationalFactQA所揭示的挑战和机遇无疑将激励更多创新技术的诞生。面向未来,结合多模态融合、自监督学习及强化学习等先进技术,有望显著提升大型语言模型在复杂表格数据事实检索上的性能表现。总之,RelationalFactQA标志着一个新的里程碑,为实现更精准、更可靠的智能信息检索奠定了坚实基础,也为推动人工智能服务更广泛的实际应用开辟了道路。
。