大型语言模型(LLM)的出现极大地推动了自然语言处理领域的发展,使得机器越来越能够理解和生成符合人类语言习惯的内容。然而,构建并训练一个高效、稳定的LLM并非易事,其中隐藏着诸多复杂的数学和计算难题。层归一化(Layer Normalization, LayerNorm)作为一种关键技术,扮演着维护模型训练稳定性及性能优化的重要角色。要真正理解层归一化的价值和操作机理,我们需要先从模型本身的结构和训练过程谈起。 大型语言模型一般包含多个网络层,每层都会对输入数据进行复杂的变换。在训练过程中,模型会根据预测结果与真实标签之间的误差,通过反向传播(backpropagation)算法更新权重参数。
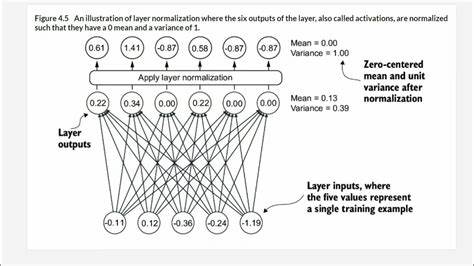
反向传播核心的计算依赖于梯度,梯度的大小决定了模型参数调整的幅度。然而,在多层网络中,梯度在传播过程中往往会经历指数级变大或变小的变化,这便是所谓的梯度爆炸或梯度消失问题。这些现象使得模型难以收敛或者学习缓慢,严重影响训练效果。 层归一化正是为了缓解这类问题而提出的技术。其基本思想是对每个输入样本在特征维度上进行归一化,使得每个输入向量的均值为零,方差为一。具体而言,对于多头自注意力机制(Multi-Head Attention, MHA)输出的上下文向量,每个向量代表一个词汇的语义表达。
层归一化会针对这些上下文向量的每一行(即每个token对应的嵌入向量),计算它的均值和方差,再对向量的各个维度进行相应的标准化处理,使其在维度上保持零均值单位方差。 通过这种处理,层归一化解决了输入信号在网络各层之间尺度不一的问题,减少了梯度在传播过程中的扭曲。同时,它避免了输入特征因不同分布带来的训练不稳定现象。形象来说,可以将模型输入看作一组音频信号,不同信号的基线电压(均值)和音量(方差)各不相同。如果不经过校正,就像直接把高音量和低音量的信号一同混音,最终会导致某些声音被压制或过强,从而影响整体效果。层归一化如同调音师,将这些信号调节到统一的基线和音量,保证后续处理的稳定与合理。
在数学上,均值的计算是简单的算术平均,将每个维度的数值求和后除以维度数量。方差则是衡量数据离散程度的指标,它是各个数与均值差值平方的平均。为了进行归一化,先将每个元素减去均值,消除偏移,确保数据围绕零分布;再除以标准差(方差的平方根),统一数据的分布尺度,防止任一维度数值过大或过小。 值得注意的是,归一化过程中除以标准差而非方差,源于统计学中的单元(单位)一致性考虑。假如将向量的测量单位设为米,那么均值是以米为单位,差值的平方则是平方米。方差单位为平方米,与原始数据存在量纲差异,直接用方差来缩放会破坏单位一致性。
而标准差单位仍为米,作为分母使用更契合原始单位,使得归一化后数据无量纲,更便于模型处理中间特征的学习。 然而,层归一化中对上下文向量进行归一化的操作似乎会影响它们的语义含义,尤其是均值调整会改变嵌入向量的方向。由于语言模型中向量的方向通常携带丰富的语义信息,乍一看似乎会损害模型效果。但实际情况是,真实训练中模型整体以最终输出的误差函数为优化目标,训练过程带有层归一化,促使权重参数自适应地调整,使得未经归一化的中间表示无需直接具备可解释意义。换言之,多头注意力机制内部参数的训练会妥善适应归一化操作,为最终输出传递有效的信息。 此外,层归一化并非单纯把所有向量都强行变成零均值和单位方差。
模型中还引入了可训练的缩放参数(scale)和偏移参数(shift),它们与上下文向量的维度一一对应,用来对归一化后的向量进行线性变换。这一步允许模型学习最适合的数值分布状态,避免因固定统计属性限制而丧失表达能力。可以类比为调音师在初步归一音量之后,根据音乐作品的风格与效果需求,微调各音轨的响度和均衡,实现更符合整体表现的结果。 层归一化的优点不仅体现在梯度稳定性上,还加快了训练收敛速度,提升了模型泛化能力。它相比批归一化(Batch Normalization)更适合于序列模型,如变换器架构(Transformer)中,因为序列长度往往变化且实时输入,层归一化能即时针对当前样本自身进行归一操作,而批归一化依赖于批量统计数据,处理动态序列时存在限制。 总的来说,层归一化不仅是大型语言模型从理论到实践的重要环节,更是底层训练逻辑的有力保障。
它通过对模型内部的激活进行标准化处理,稳固了数字运算基础,避免了梯度消失与爆炸的陷阱,促进了更深层次、更宽更复杂结构的高效训练。未来在不断发展的自然语言处理领域,层归一化的理念和技术仍将被进一步完善和应用,助力打造更智能、更健壮的语言模型。