在人类认知科学和人工智能领域,视觉信息的处理一直是研究的核心。大脑如何感知、解码并理解复杂的视觉场景,不仅关乎认知神经科学的基础问题,也为构建更智能的人工系统提供了重要启示。近期的科研发现显示,人类大脑在对视觉场景进行高层次表征时,与大型语言模型(Large Language Models, LLMs)所生成的语义嵌入空间呈现出惊人的一致性。这种跨模态的契合揭示了视觉认知与语言理解之间更为紧密的联系,开启了理解大脑信息处理机制和优化机器学习模型的新视角。 人类视觉系统不仅仅识别物体,更会综合物体的空间关系、语义关联以及环境交互,形成对场景的整体感知。传统的神经科学研究多关注对单一物体的识别和定位,但现实世界的视觉输入远比物体本身复杂,其所蕴含的上下文信息、场景语法甚至行动意图都是理解视觉的关键。
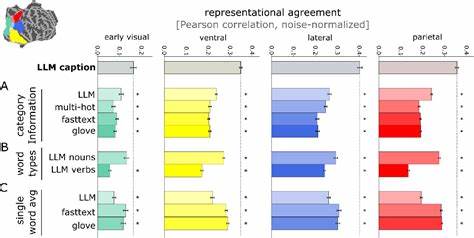
相较之下,大型语言模型通过对大量文本数据的深度学习,能够捕捉语言的语义层次和世界知识,形成高度概括且具上下文感知能力的语义嵌入。这些模型虽然未直接接受视觉信息训练,却在语义层面能够反映出丰富而细致的世界知识。 通过结合7特斯拉功能性磁共振成像(fMRI)技术和人工神经网络模型,研究者得以同时采集和分析人类大脑在观看自然场景时的活动模式,以及相应场景描述文本经过LLM编码后生成的嵌入。结果显示,基于场景描述的LLM嵌入与大脑中多个高级视觉皮层区域的神经活动模式高度匹配。特别是在腹侧、侧面和顶叶视觉流的高级区域,这些文本生成的语义表征能够有效预测对应的视觉脑活动。这种跨模态关联不仅表明语言模型的语义空间反映了视觉认知中关键信息的组织,还暗示大脑处理视觉信息时,可能将视觉输入映射到一种类似语言模型的多维语义空间。
这一发现带来了多个重要启示。首先,它强调了视觉认知与语言理解并非孤立运作,而是通过共享的高维语义表征进行信息交互。这一机制或促进了不同认知系统间的有效沟通和整合,使人类能够更灵活地推理和理解环境。其次,在人工智能领域,该研究成果表明将视觉模型的训练目标设定为预测LLM语义嵌入,可以显著增强模型对人脑视觉表征的仿真能力。相比传统基于物体分类的训练方法,这种以语言驱动的训练范式能够捕获更加丰富、复杂的视觉信息,提升模型对场景语义的理解深度。 深入分析表明,LLM的优势在于其对句子整体的语境理解,而非单纯依赖单词或类别标签。
模型中对整个场景描述的编码,涵盖了名词、动词及其相互关系,这种复杂的信息整合正是促成与大脑表征高度对齐的关键。在不同大脑区域的功能选择性体现上,基于LLM嵌入构建的线性编码模型能够还原人类脑中对人物、场景和食物等不同类别特异性的激活模式,验证了该表征的生物学相关性。此外,使用简单的线性解码方法还可以基于脑活动重建相应的文本描述,显示了这种语义表征的可解释性和实用性。 研究人员进一步构建了视觉输入至LLM嵌入空间的深度神经网络模型,这些模型通过训练实现了从图像直接预测LLM表征的能力。令人惊讶的是,尽管训练数据量远少于其他先进视觉模型,这些模型在模拟人脑的视觉表征方面表现出更优的效果,进一步证明了使用语言驱动语义空间作为目标的有效性。由此可见,将视觉处理映射到语言模型语义空间,不仅是大脑潜在的处理策略,也可能是设计高效视觉认知人工系统的关键路径。
这些发现也为认知神经科学领域带来了挑战与机遇。传统的视觉研究框架较多聚焦于低级视觉特征或单一类别识别,而LLM嵌入体现在语义和上下文的综合整合,提供了一种全新的双语义层次:既保留了视觉细节,也融合了语言中的复杂语义。因此,未来的研究可以考虑将多模态的信息嵌入纳入大脑表征的解析框架,结合视觉、语言和认知功能多维度理解大脑信息处理的整体机制。 此外,这种大脑与LLM表征的深度契合对神经解码技术具有重大意义。通过模型预测脑活动对应的文本表述,可以实现更加精准和自然的脑机接口应用,推动脑信号直接转化为语义信息,为神经康复和人机交互开启新篇章。再者,利用LLM嵌入作为神经活动的描述格式,有望统一不同脑区间的跨模态信息交流机制,促进对大脑多任务协同工作的理解。
需要指出的是,尽管LLM嵌入很好地逼近了高级视觉皮层的表征,视觉系统中仍然保留了一部分纯视觉信息,这些信息可能未被语言描述完全覆盖,如物体的精确位置等。因此,结合视觉直接输入的人工神经网络模型在预测脑活动方面表现优于单纯的LLM嵌入,强调了视觉信息与语言信息的互补性。 综上所述,人脑视觉表征与大型语言模型的语义嵌入空间之间的高度一致,展现了视觉认知与语言理解的跨模态共鸣,挑战了传统认知神经科学的单一感官视角。利用语言模型提供的复杂语义结构,不仅帮助揭示大脑如何综合处理丰富视觉信息,也为设计更智能的人工系统提供了新的范式。未来深入挖掘此类跨模态表征的本质和机制,将极大推动脑科学与人工智能的融合发展,推动人类对智能本质的认知迈上新台阶。 。









