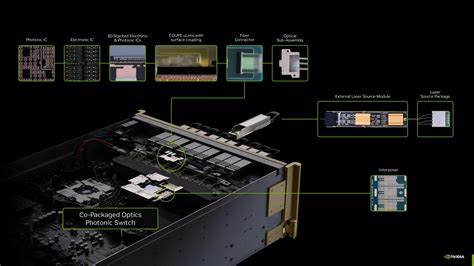
随着生成式人工智能和大规模模型训练对计算与通信需求的急剧上升,传统铜缆互连在带宽、能耗和散热方面的局限变得越来越明显。GPU密集型集群要求将海量数据以极低延迟送入加速器,同时尽量减少功耗带来的热量累积。光子交换机与共封装光学(CPO)技术因此成为行业关注的焦点,它们承诺用光替代电,在速度与能效之间找到新的平衡点。 共封装光学的核心理念是把光学器件与处理器或网络芯片封装在同一基板上,缩短电连接路径,减少电信号与铜缆在高频下的损耗。相比传统以太网铜缆或板级高速差分对,CPO方案能够在每通道更高的数据率下保持更低的能耗,同时显著降低随距离增加的信号衰减,这对于地域扩张且节点间物理距离不断拉长的超大规模AI数据中心至关重要。 产业层面已有显著进展。
Nvidia推出的Spectrum-X Photonics与液冷的Quantum-X Photonics代表了GPU厂商在CPO领域的早期布局。Spectrum-X定位于以太网生态,目标是实现每条通道200Gbps的速率;Quantum-X则面向高性能互连,提供面向InfiniBand的800G连通性,优先满足训练集群对低延迟、高带宽的苛刻需求。Nvidia的举措表明,厂商正在把光学互连作为下一代加速器系统设计的标配方向。 芯片级与系统级的整合来自半导体与光子公司之间的协同。Broadcom长期致力于将网络ASIC与光学引擎集成到同一封装,早期产品已实现从100G到400G每通道的跃迁。其Tomahawk系列从Tomahawk 4的混合通道到Tomahawk 6支持400G/通道的最新测试,展示了按代进化的路线图。
Broadcom与Meta合作在高温实验室进行了严苛测试,模拟了数百万小时的400G端口运行而未出现"链路抖动",为CPO进入生产环境提供了可靠性层面的重要背书。 在光子器件方面,新兴公司也在加速技术成熟。NLM Photonics的硅有机混合(SOH)光子集成电路在实验中展现了1.6T与3.2T的潜在通道能力,224Gbps/通道的测试结果证明了商业化200G级别性能的可行性,并为向400G演进铺平道路。SOH方法通过在硅波导上集成有机电光材料,实现更高的调制效率与更小的器件占位,从而在带宽与封装密度上取得优势。 Aloe Semiconductor在调制器设计上的进展同样引人注目。其在ECOC展会公布的180-Gbaud PAM4测试相当于360Gbps单通道速率,且在现有晶圆代工流程下实现高频性能的方式,有望把单波长带宽推向425Gbps而无需大规模改变制造工艺。
这一点对产业链非常重要,因为现有的制造生态可被延用,降低了商业化障碍。 除了器件本身,系统集成商也在探索不同的实现路径。Micas Networks等公司将Broadcom的交换芯片与多颗光学芯片组合到4U机架单元中,提供128个400G FR4光纤端口的高密度解决方案,这种模块化封装有助于数据中心在有限机架空间内获得更高的端口密度与带宽支撑。 光子交换机带来的直接好处包括带宽密度显著提升、每比特能耗下降,以及降低整体散热负担。把光学器件靠近处理器封装后,电源与信号线的热量集中问题有所缓解,整个交换与互连系统的冷却效率得以提升。液冷配合CPO的方案在短期内可能成为高性能训练集群的主流,因为液冷能够把剩余热量更高效地带走,保障更高的芯片频率与稳定性。
尽管前景光明,挑战仍然存在。第一是制造与良率问题。将光学元件与高速网络ASIC co-package对封装精度、热膨胀匹配以及互连可靠性提出了极高要求。任何微小的光学对准误差或材料不匹配都可能影响链路稳定性。第二是成本问题。尽管随着规模化和设计成熟成本会下降,但早期部署的资本支出仍然显著高于成熟的铜缆系统。
第三是标准化与互操作性。业界需要统一接口规范、光学封装标准以及测试方法,才能实现不同厂商产品之间的无缝互联与替换。 在生态与供应链层面,硅光子与传统半导体产业的融合需要时间。硅光子器件往往需要特殊的掺杂、互联和封装步骤,如何在现有晶圆厂流程上平滑集成并保持可扩展性,是供应链必须解决的问题。部分公司选择通过硅有机混合或新型调制器设计来缓解加工复杂度,而另一些则通过与成熟Foundry合作来推动量产化。 从运维角度看,光学互连的监测与故障诊断体系也需同步升级。
传统网络故障诊断工具针对电信号特征优化,而光路故障可能表现为链路功率下降、波长漂移或器件损伤。数据中心需要在监控、测试与自动化修复层面投入,以确保光子交换机在复杂工作负载下的稳定运行。 产业投资与合作正在加速这一转型。Nvidia对硅光子生态的战略投资、Broadcom与社交与云巨头的联合测试、以及新创企业在器件创新上的突破,都表明从研发走向部署的路径正在形成。与此同时,围绕开放互连协议与可扩展互联方案的新兴标准组织,如Upscale AI等,正努力把接口标准化以促进更广泛的行业采用。 展望未来几年,光子交换机在AI数据中心的部署将呈现分层推进的态势。
在顶层交换与叶脊级别,400G及以上的CPO解决方案将首先在追求极致性能与能效的训练集群中落地。在更广泛的以太网与边缘场景中,200G级别的光学端口将以较低的成本和更高的兼容性逐步替代铜缆连接。长期来看,随着每通道速率提升到400G甚至更高,光子化将成为数据中心网络架构的默认方向。 对于企业与数据中心架构师而言,当前时期是评估并试验CPO与硅光子技术的关键窗口。需要考虑的因素包括当前与未来工作负载的带宽需求、冷却能力与数据中心布局、预算与替换周期、以及与现有网络设备的兼容性。试点部署应侧重在高价值的训练集群或跨机架带宽瓶颈最明显的环节,从而在可控风险下验证可观性能收益。
总的来看,光子交换机并非单纯的组件升级,而是推动数据中心架构、散热策略与产业链协作的系统性变革。它承诺把GPU"喂饱"而不产生无法承受的热量,从而让规模更大、速度更快、成本更可控的AI训练与推理成为可能。随着器件成熟度提高、测试验证累积和标准化推进,光子化互连将在未来几年内成为支持大规模AI计算的核心技术之一。 。









