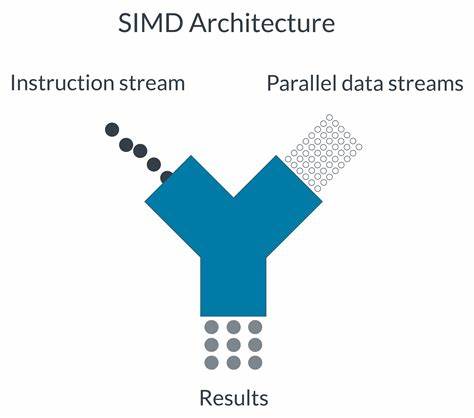
在现代计算领域,数据并行处理技术成为提升性能的关键,尤其是在移动设备和嵌入式系统上,Arm架构的广泛应用让SIMD(单指令多数据)技术日益重要。本文将深入解析Arm SIMD循环的实现方式,重点围绕C语言实现、Arm C Language Extensions(ACLE)内插函数以及Neon、SVE和SME三种主要向量扩展技术,帮助开发者全面理解与掌握这一领域的核心技术,从而在实际应用中发挥出最大的性能优势。 Arm SIMD技术的核心思想是通过单条指令并行处理多个数据元素,显著提升计算效率,相较于传统的标量处理,其在多媒体图形处理、音视频编码、人工智能推理等场景中表现尤为突出。Arm架构提供了多种实现SIMD的方案,其中Neon是早期旗舰SIMD技术,SVE是针对高性能计算提出的可扩展向量扩展,而最新的SME则在SVE基础上进一步强化了矩阵引擎功能。 在软件开发过程中,利用C语言高效实现SIMD循环是关键技能。通过标准C代码,开发者可以实现高效的循环结构处理数据,但纯C代码往往难以精准利用底层SIMD指令优势。
为此,Arm生态系统提供了ACLE内插函数库,这是一套专门针对Arm处理器向量指令设计的函数接口,可以直接调用底层SIMD指令,避免手写汇编的复杂性和易错性。通过ACLE,C语言程序员能够实现针对Neon、SVE及SME等不同指令集的优化方案,完成高性能计算需求。 Neon技术是Arm 处理器中广泛支持的SIMD扩展,提供了128位向量寄存器和丰富的指令集,实现音视频编解码、多媒体算法加速等任务极为高效。Neon支持单指令操作多个8、16、32位整数或浮点数数据,满足了大量嵌入式设备对低功耗高性能的需求。在C语言层面,利用ACLE内插函数,开发者可直接调用Neon指令实现矢量加载、存储、算术和逻辑操作,极大简化了开发流程,并增强了代码的性能表现。 相比Neon,SVE(Scalable Vector Extension)具备灵活向量长度,支持从128位到2048位向量寄存器,具备极高的可扩展性,面向未来大规模并行计算任务。
SVE的设计更注重高性能计算领域,如深度学习训练和科学计算。SVE的编程模型支持自动向量化循环和向量长度无关的算法设计,让代码更加具有适应性和可移植性。通过ACLE,开发者无需关注底层具体向量寄存器的宽度,即可编写高效且可伸缩的矢量化循环。 SME(Scalable Matrix Extension)是在SVE基础上的进一步扩展,专为矩阵运算优化设计,特别适合机器学习和大规模线性代数计算应用。SME引入了矩阵寄存器和专用指令集,实现复杂的矩阵乘法、加法等操作的硬件级加速。SME不仅提升了计算密度和吞吐量,还显著降低了数据搬运和重新计算的开销。
当前,SME的软硬件生态还在逐步完善,但具备极大的发展潜力,是未来高性能计算领域的关键技术之一。 除了利用ACLE内插函数实现SIMD循环外,借助内联汇编技术直接嵌入Arm汇编指令也是一种常见做法,尤其在需要极致性能的场景下。内联汇编允许开发者亲自控制寄存器分配、指令调度和流水线资源,做到最细粒度的优化。但这也带来了更高的开发复杂度和维护难度,同时可能影响程序的可移植性。因此,在大多数情况下,优先选择ACLE内插函数实现向量化的方案更为推荐。 在实际应用开发过程中,充分考虑SIMD循环的设计原则至关重要。
合理利用数据对齐、避免内存访问瓶颈、防止分支跳转中断流水线、选择合适的循环展开与向量化策略,都能极大提升程序运行效率。对Neon、SVE和SME的特性有深入理解,能帮助开发者针对不同硬件平台和应用需求,选择最合适的技术方案,发挥Arm架构的最大潜能。 近年来,随着人工智能和边缘计算的蓬勃发展,Arm SIMD技术受到越来越多的关注与重视。一方面,Neon已经成为嵌入式设备和智能手机中的实用利器,另一方面,SVE和SME代表了Arm在高性能计算领域的前沿创新。企业和开发者纷纷利用这些技术构建性能优越的应用,在机器学习推理、图像处理、大数据分析等领域实现突破。 总结来看,Arm SIMD循环技术涵盖了从基础C语言实现到低层汇编优化的全方位工具链,ACLE内插函数的引入大大降低了复杂度,而Neon、SVE与SME技术的迭代,则为不同应用场景提供了丰富的性能提升手段。
系统地掌握这些技术,不仅有助于提升代码效率,也能有效缩短开发周期和降低成本。无论是移动设备开发者,还是高性能计算工程师,都应深入研究Arm SIMD生态,实现软硬结合的最优性能表现。在未来计算时代,熟悉并精通Arm SIMD技术无疑是一项必备的核心竞争力。 。