近日,来自中国的研究团队 DeepSeek 发布了一款名为 V3.2-exp 的实验性大模型,核心亮点是其所采用的"稀疏注意力"(Sparse Attention)机制,据称在长上下文场景下可以将 API 推理成本降低近一半。V3.2-exp 在 Hugging Face 上以开放权重的形式发布,配套论文和技术细节也同步公开,使得社区可以进行独立验证与二次开发。对于需要处理大文本输入、长文档检索或多轮长历史对话的应用场景,这类优化有可能带来显著的成本与性能提升。本文将从技术原理到实战部署、测试方法以及产业影响等方面对 V3.2-exp 与稀疏注意力设计做详尽解读,帮助工程师、产品经理和技术决策者快速评估其价值与落地路径。 稀疏注意力的基本动机来自传统 Transformer 在长上下文下的计算瓶颈。标准自注意力机制的计算复杂度与输入长度的平方成正比,随着上下文窗口从几千 tokens 增长到上万,内存与算力成本迅速攀升,直接导致推理延迟变大和 API 成本上升。
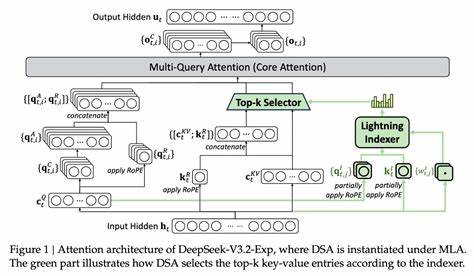
为了解决这个问题,研究者们提出了不同的近似策略:局部注意力、分层注意力、稀疏矩阵近似以及检索增强等。DeepSeek 的 V3.2-exp 在这些思路上引入了两层选择机制:一是"lightning indexer"(闪电索引器),用于在长上下文中快速识别出与当前查询最相关的片段;二是"fine-grained token selection system"(细粒度令牌选择系统),用于在被选中的片段内部进一步挑选关键 tokens 进入有限的注意力窗口。两层联合工作,使得模型可以在保持对重要信息关注的前提下,大幅削减每次推理所需加载和计算的上下文量。这样的设计既保留了长上下文的语义连贯性,又降低了计算开销。 从工程实现角度看,lightning indexer 更像是一种高效的检索前置模块。它可以基于轻量级的向量索引、稀疏哈希或可学习的打分器,先以粗粒度对上下文进行排序,快速筛出若干相关片段。
随后,细粒度选择模块会对这些片段做更精细的筛检,挑出对生成或推理最有价值的 tokens,例如实体、时间、关键短语或上文的答案线索。通过这种两步走的 pipeline,整个系统避免了将完整长文全部送入 Transformer 的昂贵自注意力层,而是只将最关键的一小部分令牌纳入计算范围。实践中,lightning indexer 的实现可以使用 CPU 优化的向量搜索、量化索引或者 GPU 端的低延迟哈希算法,细粒度选择则可以通过可学习的门控网络或者启发式规则实现。 DeepSeek 在其初步测试中宣称,针对长上下文调用,简单的 API 请求成本能够下降约 50%。需要强调的是,这类降成本比例高度依赖具体任务类型、上下文结构和实现细节。在以长文档问答、多文档汇总或长对话建模为主的场景里,相关信息往往只分布在文档的若干片段中,稀疏注意力机制可以以极小的损失换来显著的计算节省。
而在那些需要全局一致性或跨全文细微关系推理的任务中,过度稀疏化可能导致性能下降,因此实际收益需要通过系统化的 A/B 测试和评估指标来量化。 开源与社区验证是 V3.2-exp 的一大优势。把模型权重和论文放在 Hugging Face 和 GitHub 上,意味着学术界和工业界可以快速复现 DeepSeek 的实验,甚至在不同硬件与不同数据集上进行对比测试。对于云服务提供商、模型部署工程师和研究者来说,复现流程包括:下载模型权重、加载模型到常见推理框架(如 PyTorch/Transformers、ONNX、TensorRT)、构建 lightning indexer 与 token selection 的原型实现,并在代表性任务集上衡量吞吐量、延迟与成本。理想的评估应包括 end-to-end 延迟(含索引与选择开销)、内存占用、每次请求的实际计算 FLOPs 以及生成质量指标(如准确率、ROUGE、BLEU、或人类判断)。 在实际落地时,工程团队需要权衡若干关键点。
第一,索引器的构建与维护成本:如果上下文经常变化,则索引需要频繁重建或在线更新,这会增加系统复杂度。第二,容错与回退策略:在筛选模块失误导致关键信息被遗漏时,系统需要有补救机制,比如按置信度回退到更广的上下文窗口或触发二次检索。第三,延迟敏感性:lightning indexer 的前置检索可能带来额外延迟,尤其是在高并发场景下,因此要优化索引查询的并发性与缓存策略。第四,安全与隐私:当上下文包含敏感数据时,索引与选择模块的设计需确保不会引入新的泄露风险或违反数据合规要求。 从商业角度分析,稀疏注意力若能在大规模生产环境中稳定运行,将对 API 定价模型、云算力采购和产品设计产生重要影响。许多企业在使用大型语言模型时面临的主要挑战是推理成本不透明且高昂,特别是在处理长文档和批量请求时。
若 DeepSeek 的方法被证明可在普遍场景下稳定实现 30% 到 50% 的成本削减,云服务商与模型提供方可能被迫调整定价策略,或将类似的稀疏机制内嵌到商业模型中以维持竞争力。另一方面,开源模型的可用性也意味着中小企业与创业团队能够以更低的成本构建长上下文应用,从而激发更多创新场景,例如法律文件自动化审阅、医学影像长文档分析、科研综述自动生成和跨文档知识融合等。 技术社区也会对稀疏注意力展开广泛的延伸研究。一个重要研究方向是如何在稀疏化和性能之间找到最佳平衡,使得模型在大幅降低计算量的同时,不显著牺牲生成质量。此外,如何将稀疏选择与检索增强生成(RAG)等架构结合,是另一个值得探索的方向:RAG 使用外部检索来补充上下文,稀疏注意力则在模型内部选择最关键的 tokens,两者结合可以形成外部检索到内部稀疏化的端到端优化流程。还有机会探索可学习的稀疏化策略,即通过训练让模型自己学会在哪些位置放置注意力,而不是依赖固定启发式规则。
模型评估方面,建议采用多维度的评测方法。核心指标包括生成质量(如准确性、一致性与连贯性)、延迟(端到端请求时间)、资源消耗(内存与显存占用)、每次请求的实际成本估算以及错误模式分析。为避免单一任务偏见,应在问答、摘要、对话、代码理解等多种任务上测试 V3.2-exp 的表现。另外,进行人类评估尤为关键,尤其是在判断生成文本是不是丢失了关键上下文信息以及模型是否引入不一致或编造内容时。 对开发者的实用建议包括若干方面。部署前应先在小规模 representative 数据集上进行压力测试,评估索引器的建立与更新开销。
在生产系统中,务必实现分级回退策略:当细粒度选择置信度过低时回退到更宽松的上下文窗口;当索引延迟超阈值时使用缓存的最近结果以保证延迟可控。成本监控不可或缺,建议在推理链路中埋点收集每次请求的上下文长度、被挑选 token 数量、索引查询时间以及生成时间,用于持续优化节省与质量之间的权衡。 从全球视角来看,DeepSeek 的工作也反映出中国 AI 团队在模型效率与工程化方面的持续进步。此前 DeepSeek 的 R1 模型因在训练阶段采用低成本的强化学习策略而受到关注,而 V3.2-exp 则聚焦于推理阶段的工程问题:如何在实际部署中降低长期运营成本。对于整个行业而言,这类以工程和成本为导向的创新同模型性能优化一样重要,因为长期可持续性与成本可控性决定了模型在产业化进程中的可承受性与扩展性。 当然,稀疏注意力并非银弹。
一方面,对于需要复杂全局推理或跨长距离依赖的任务,过度稀疏化可能导致模型忽视细微但重要的联系,从而出现错误或不一致。另一方面,索引器或选择器自身带来的工程复杂度、维护成本以及潜在的系统不稳定性也是必须考虑的因素。因此在采用稀疏注意力方案时,团队应以场景驱动评估,选择合适的稀疏化强度与可靠的回退机制。 展望未来,稀疏注意力技术可能与多模态模型、分层记忆机制以及自适应计算策略形成良性组合。比如在多模态长上下文场景下,lightning indexer 可以跨文本、图像和表格等多种模态建立统一的相关性评分,从而在更复杂的输入结构中实现有效稀疏化。此外,结合动态计算预算分配(根据请求的重要性动态调整注意力预算)可以让系统更经济地使用算力资源。
最后,社区和产业界的广泛试验将推动更成熟的实现模式与标准化工具链出现,从而降低采用门槛。 总结来看,DeepSeek 推出的 V3.2-exp 和其稀疏注意力设计为解决长上下文推理成本问题提供了切实可行的路径。通过 lightning indexer 与细粒度 token selection 的组合,模型在长文本场景中实现了显著的计算节省潜力。对于希望优化推理成本的团队而言,V3.2-exp 的开源发布提供了一个可供试验和借鉴的参考蓝图。但在落地前,必须通过多维度评估与周全的工程保障来权衡效率与质量。未来,随着更多团队在不同任务和硬件环境中验证与改进稀疏注意力机制,我们有望看到这一类方法成为处理超长上下文问题的重要实践路径,并推动大模型在商业化部署中的可持续发展。
。