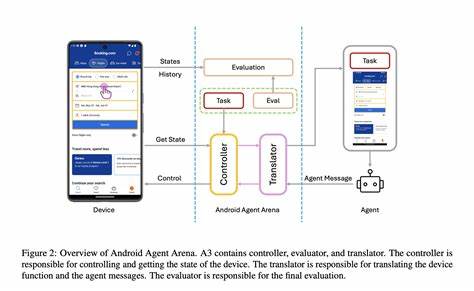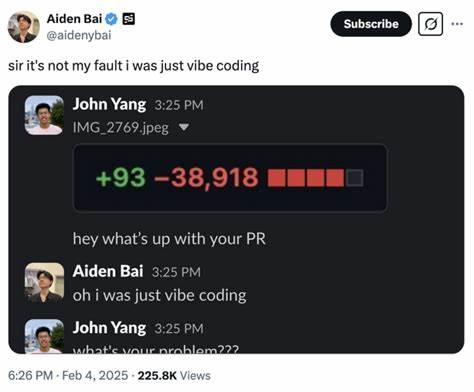
近年来,随着人工智能技术的迅速发展,编程世界逐渐被一种全新的现象所影响——“氛围编码”(Vibe Coding)。这个现代词汇描述了在AI辅助下带有一定随意性但高效的代码编写方式。尽管氛围编码一度被称为“潮流”或“趋势”,然而它所带来的利弊和深层次的问题也引发了诸多技术人的关注与争议。作为一名活跃于测试领域并深度应用AI的程序员,我深感这个话题不仅关乎代码的未来,也关乎整个软件开发生态的变革方向。首先,我们不得不承认AI在代码生成上的巨大潜力。大型语言模型(LLM)可以帮助程序员写些基础的样板代码、自动补全测试中的模拟数据,甚至生成简单的原型代码,极大地提升了编码效率。
然而,现实证明,这些模型在处理复杂问题时仍然面临诸多限制。以我个人经历为例,曾在解决“ESM地狱”环境下运行playwright测试子进程的复杂问题时,不论我尝试调用哪个语言模型,得到的答案都不比StackOverflow上的经验分享更有效。其实,这并不意外——语言模型依赖于其训练数据,无法突破既有知识框架,面对鲜有先例和复杂边缘情况时效果有限。事实上,真实的软件开发中,花费时间最多的恰恰是这些“长尾问题”,它们往往无法被现有的AI轻松攻克。与此同时,氛围编码所引发的另一个核心问题则是代码质量与可维护性的隐忧。AI生成的代码虽然快速,但并非总是最佳实践的体现,甚至可能包含隐秘的缺陷。
一个有趣而又令人担忧的现象出现在GitHub Copilot参与开源项目时,社区曝光了它提交到.NET运行库中的一些奇怪甚至滑稽的PR。这些PR不仅反映了AI生成代码的潜在风险,也揭示了程序员在审查AI代码时所面临的巨大认知负担。毕竟,为了确保代码无误,人类审查者必须比以往更加深入理解问题本质,花费更多精力。对于测试领域而言,氛围编码和AI自动生成代码带来的挑战尤为明显。AI生成的软件若由另一台AI负责测试,风险将成倍增加,因为这种闭环反馈容易导致“模型崩溃”,即错误被不断放大、循环强化。想象一下,如果应用程序的测试全部由AI自动生成和执行,而缺少人工参与,很可能陷入“自证自明”的陷阱,导致软件质量无法得到有效保障。
因此,尽管AI能协助测试,最终的审核环节仍然离不开人类的判断和监督。这种观点也得到了学术界的支持,表明人机协同而非完全自动化是当前阶段最稳妥的方式。面对这样复杂的局面,我们不妨重新审视氛围编码的定位。氛围编码并不是对代码质量的放弃,而是对效率与创造力的追求,同时,必须清楚地意识到其局限性和潜藏风险。团队内部对待AI的态度往往出现分歧,一些成员乐观期待,另一些则持保留态度。事实上,正确使用AI才是胜出之道:将其作为辅助工具,在合适的场景下使用,监控并纠正其可能的偏差,而非盲目依赖或完全排斥。
作为Octomind的技术负责人,我深感将AI与端到端测试完美结合的潜力。通过智能的定位选择和直观的界面设计,我们团队致力于打造不仅是生产效率的提升,更是对质量的严格把控。我们坚信技术的发展必须以人为中心,兼顾创新与风险防控,确保最终交付的产品符合预期规格。回顾整个发展历程,氛围编码的兴起不仅反映了人工智能技术的突破,也暴露了产业对自动化过度乐观的盲点。编程仍然是一门需要冷静思考、充分理解问题背景和细节的艺术,AI虽然是强大工具,却无法完全替代人类的创造力和经验判断。未来的道路或许是人机协作的新时代, AI帮助程序员解决繁琐的工作,而开发者专注于真正复杂和创新的任务。
同时,测试作为确保软件符合规范的最后防线,更应该谨慎对待AI的引入,避免质量坍塌。总结来看,氛围编码不仅是一种编码方法论,更是一场关于软件开发理念的思考。程序员们对“氛围编码”的批判与期待,构成了一种健康的技术自省,推动行业避免盲从,理智拥抱智能化工具。在这场变革中,每一位开发者的声音都至关重要。或许,只有当我们能够平衡效率与质量、乐观与谨慎、创新与稳健,才能迎接一个真正成熟的智能编程时代。