在当今信息爆炸的时代,向量索引技术成为处理海量数据和实现高效搜索的关键工具。特别是图基向量索引,以其独特的数据结构和算法优势,逐渐成为机器学习、自然语言处理以及推荐系统中的热门方向。本文将围绕图基向量索引展开讨论,深入分析其工作原理,并通过“FES定理”来解释这一技术的核心逻辑,帮助读者全面理解图基索引的本质和应用价值。 理解图基向量索引的第一步是认识向量检索的背景。传统的关键词检索方法在面对复杂的语义表达时显得力不从心。向量检索则通过将文本、图像等多模态数据转化为多维向量,基于相似度进行查找,从而大幅提升搜索的准确性和效率。
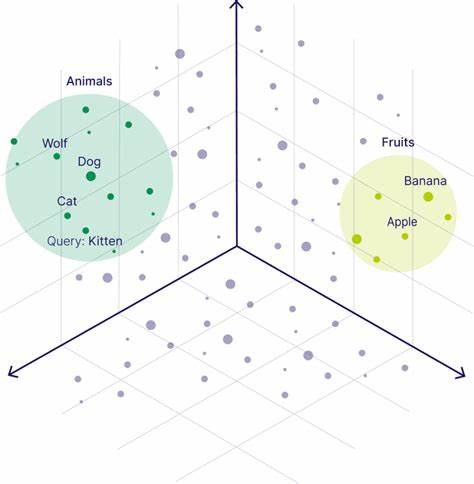
在此基础上,向量索引负责组织和管理这些海量向量,使得检索过程快速且精确。图基向量索引正是通过构建图结构来实现这一目标,它将数据点视作图中的节点,利用图中的边表示节点间的相似关系,形成高效的导航网络。 图基向量索引的优势在于其良好的扩展性和动态更新能力。相比传统的倒排索引或树形结构,图结构允许在高维空间中更好地捕捉局部邻域信息。例如,对于一个数据点,其连通的近邻节点存在着密切的相似关系,通过遍历这些边,可以快速找到最近邻,从而极大减少搜索空间和查询时间。这种结构非常适合高维度、多样化的数据环境,如影像识别中的特征匹配、文本语义相似度计算等。
然而,构造高效的图基向量索引并非易事。它面临着如何平衡索引构建成本、查询效率以及准确性的挑战。在此背景下,“FES定理”应运而生,成为理论指导和实践优化的重要工具。FES定理全称为“Fast Expansion and Search theorem”,即快速扩展与搜索定理。它揭示了图的拓扑结构与近邻搜索性能之间的深层关联,为索引设计提供了数学依据。 FES定理核心思想是分析图中节点的连接方式如何影响搜索的路径长度和覆盖范围。
通过合理设计图的边连接策略,使得网络能够快速扩展,覆盖更多高相似度邻居,同时保证查询路径短且精确性高。定理指出,当图结构满足特定的扩展性质,搜索算法可以在对数时间内高概率找到真实的近邻,实现高效而准确的检索。这一理论突破填补了图基索引中性能分析的空白,为构造高效索引指明了方向。 结合FES定理,研究人员提出了多种图基索引算法改进方案。例如,基于近邻传播的图构造技术,能够动态调整节点连接,优化网络扩展性能;层级图索引通过分层结构减少搜索复杂度;再如利用剪枝策略去除低质量边,强化路径引导效果。这些方法均依赖于FES定理提供的理论基础,确保算法的计算效率与检索准确性达到平衡。
在实际应用层面,图基向量索引凭借其高性能特点,在文本搜索、图像检索、语音识别等领域获得广泛应用。尤其在自然语言处理里,语义向量的高维复杂性让传统索引手段难以胜任,而图基索引能够依据语义相似度构建复杂但高效的邻域图,从而实现快速响应的语义检索。此外,推荐系统中的用户兴趣建模与商品特征匹配,也充分依赖于图基索引所带来的高效邻接关系挖掘。 未来,随着深度学习技术的不断发展和海量数据的涌现,图基向量索引将持续演进。结合FES定理,未来的研究可探索更加智能化的图结构自动设计,如自适应连接机制和动态权重调整,进一步提升检索的速度与准确率。同时,跨模态向量索引与图基结构的结合,也将成为实现多源异构数据融合的关键路径。
对企业和研究人员而言,深入理解图基向量索引和FES定理的理论与实践意义,将助力构建更加智能、高效的信息检索系统。 综上所述,图基向量索引通过图结构有效捕获数据点间的相似关系,显著提升了向量检索的效率和准确性。FES定理作为其理论基石,揭示了快速扩展与搜索的内在机理,为索引算法设计提供了重要指导。掌握这一技术,不仅有助于推动信息检索领域的创新,还能在多样化应用场景中实现数据价值的最大化。随着技术的深耕和应用拓展,图基向量索引及其理论研究必将成为未来智能搜索和数据处理的中坚力量。