随着人工智能技术的迅速发展,大型语言模型(Large Language Models,简称LLMs)已在多个领域展现出卓越的语言理解与生成能力。它们不仅能处理自然语言文本,还能辅助科学家完成复杂的推理任务和知识抽取。特别是在化学领域,LLMs带来的变革性影响引发了广泛关注。对比传统的人类化学专家,LLMs的知识结构、推理方式和实际表现呈现出独特的特点和潜力。本文将深度剖析大型语言模型在化学知识的掌握与推理能力方面的优势和不足,探讨其与人类专家的异同,并展望未来人工智能在化学研究与教育中的应用前景。 大型语言模型的兴起及其化学领域应用基础大型语言模型基于海量文本训练,通过预测下一个词汇的方式学习语言模式和知识。
随着模型规模的扩大和训练数据的丰富,LLMs在语言理解、文本生成、问答系统等任务中的表现日益卓越。近年来,研究人员将这种技术引入化学领域,尝试利用LLMs分析化学文献、预测分子性质、优化实验设计等。由于化学知识大多以文本形式存在于科学文献、教材和数据库中,LLMs能够通过对这些文本的学习,积累丰富的领域知识,并在一定程度上具备推理化学问题的能力。 ChemBench:评估大型语言模型化学能力的创新框架为了系统地测量LLMs在化学知识和推理中的表现,科研团队构建了名为ChemBench的评估框架。该框架整合了超过2700道化学问答题,涵盖广泛的化学分支和难度层级,从基础概念到高级推理均有涉及。题目类型涵盖多项选择和开放式回答,分别测试知识记忆、逻辑推理、计算能力及化学直觉等多方面技能。
通过这一框架,研究人员不仅评估了开源和闭源多款优秀LLMs的整体水平,也与化学专家进行了直接比较,为深入理解AI与人类专业水平的差距提供了数据支持。 大型语言模型与人类化学专家表现的对比分析令人惊讶的是,ChemBench的实验结果显示,当前一些顶尖的LLMs在整体正确率上甚至超过了参与实验的专业化学家。这表明,经过充分训练的语言模型能够掌握并应用大量化学知识,甚至在部分题目上实现超人表现。然而,深入分析发现LLMs在处理基础知识型问题时表现稳定,但在涉及复杂推理和结构分析的任务中仍存在明显不足。特别是在核磁共振信号数量预测等需要空间结构和对称性推理的题目上,模型表现明显落后于人类专家。 化学知识的掌握与记忆多个LLMs的表现揭示其在化学知识储备上的优势,这得益于模型训练时涉猎的大量文献资料与数据库文本。
然而,模型的知识记忆具有明显的表面性和片段性,缺乏对知识的深入理解与灵活运用。对于需要跨领域综合推理的问题,单纯依靠训练数据的记忆远远不够,导致模型容易在此类题目中产生错误或过度自信的回答。此外,当前多数LLMs未能充分集成专业化学数据库,限制了其精确查询与知识更新的能力。 推理能力的挑战与不足推理是化学研究的核心能力之一,涉及逻辑分析、数据综合和创新思维。虽然LLMs在某些推理任务中表现优异,但它们的推理方式与人类存在本质差异。模型主要依赖对训练语料中词汇和上下文的统计模式匹配,而非真正理解问题背景或分子结构的物理化学特征。
例如,对环状分子异构体数量的推断需要空间构型和化学键信息的深度理解,这是单纯文本模式下的LLMs难以胜任的任务。相较之下,化学专家能凭借多年的经验和直觉,结合理论知识灵活推理,这一优势在复杂问题面前尤为突出。 对安全性和毒性问题的应对在化学安全和毒理学相关的问题上,LLMs的表现尤为重要,因为错误信息可能带来严重后果。研究显示,部分LLMs在回答安全性问题时容易过度自信,甚至传播误导性信息。尽管某些安全领域的题目模型表现较好,达到或接近专业认证考试的水平,但更复杂或细节要求严格的问题仍有欠缺。这一点表明,LLMs在化学安全应用中需要更严密的知识验证和风险控制。
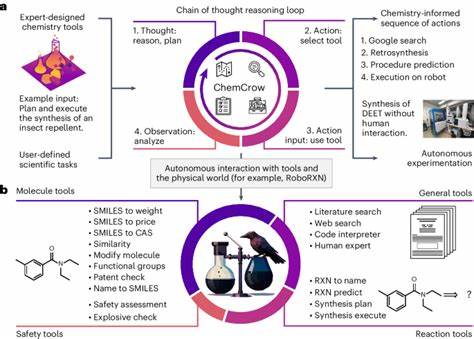
人类专家与模型的互动与工具辅助现阶段实验也强调了人类专家在使用辅助工具时所表现出的优势。在 ChemBench 评测中,参与的化学专家部分被允许使用包括网络搜索、专业软件(如ChemDraw)等工具,提升了答题精准度。相比之下,LLMs部分则通过集成检索增强生成技术尝试外部数据库查询,效果不一。由此可见,未来的化学智能体应充分结合语言模型与专业工具,实现知识检索、推理计算及经验反馈的协同工作,提升整体的科学研究实力。 未来教育与科研的启示随着大型语言模型逐渐在化学领域展现出接近甚至超越平均专家水平的能力,传统的化学教育和科研模式面临转型。未来教学应更加重视化学思维与批判性推理的培养,而不仅限于知识的死记硬背。
利用LLMs辅助教学,可降低学生接触基础知识的门槛,同时让教师有更多精力指导创新与复杂问题解决。此外,研究团队和机构可借助自动化评测框架如ChemBench,定期检测AI工具的能力更新和局限,指导模型开发与应用规范。 LLMs在材料科学与化学研究的实际应用前景除了理论问题解答外,LLMs在材料设计、反应预测、文献自动摘要等环节展现巨大潜力。结合实验自动化平台,语言模型能够实现自主设计实验方案,加速新材料和药物研发。尽管目前的模型在部分任务精确性和安全性上仍待提升,但快速迭代和与人类专家协作的策略已显现出突破的可能。 技术发展与伦理风险的权衡LLMs在化学领域的广泛应用同时引发了双重用途的安全担忧。
模型可能被利用来设计有害化学品或误导非专业用户。如何确保技术安全、负责任地传播知识,成为业界重要议题。因此,开发包含严格权限管理、内容审查和知识验证的AI平台,塑造透明且合规的技术环境,是未来的必由之路。 总结当前的研究揭示,部分大型语言模型已在化学知识与推理能力方面达到甚至超越多数人类化学专家的水平,但仍存在显著不足,主要体现在复杂推理能力、结构理解和安全性判别上。通过系统化的评估框架,如ChemBench,我们得以清晰地描绘出AI与人类专家在化学领域的能力边界。此外,未来结合工具辅助、专业数据库与更大规模模型训练,预计将提升LLMs的科学推理表现。
与此同时,化学教育和科研将因AI的加入而发生深刻变化,推动智能化、协同创新的新纪元。科学界需共同致力于打造安全、准确且高效的AI助力科研生态,促进知识传递与突破,造福社会的同时防范潜在风险。