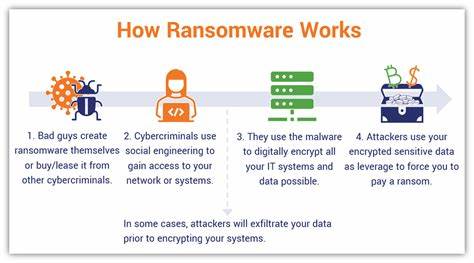
随着大型语言模型在自然语言处理领域的广泛应用,如何在资源有限的硬件环境下实现高效推理成为业内关注的焦点。gpt-oss-20b作为一款强大的开源大规模语言模型,具有卓越的语言理解和生成能力,但其巨大的参数规模通常要求高端显存配置,传统观点认为8GB GPU难以胜任此类模型。随着技术创新的发展,现有方案正逐渐打破这一限制,使得普通消费者级别的8GB显存显卡也能运行gpt-oss-20b,满足多样化的应用需求。 本文将深入分析如何在8GB显存的GPU上运行gpt-oss-20b模型,详解核心的技术流程和优化策略,全面介绍背后的关键原理及实践经验,让读者理清在资源受限环境下发挥大型模型潜力的路径。 关键技术突破之一是基于层权重的动态加载方法,它通过从SSD硬盘直接按层加载模型权重至GPU,显著降低一次性内存占用,大幅缓解显存压力。与传统将全部模型加载至显存的模式不同,这种"分层加载"避免了对显存的巨大需求,使得即使是8GB显存的设备也能维持模型正常推理。
此外,KV缓存的异地存储与高效调度也是实现低显存推理的关键。推理过程中,模型会生成过去时间步的键值缓存(KV cache),这部分数据随着上下文增大而膨胀。将KV缓存转移到SSD并在需要时实时加载回GPU,既保证了上下文长度的扩展能力,也避免了显存的爆炸式增长。 值得一提的是,gpt-oss-20b的推理过程采用了FlashAttention-2技术,这是一种在线软最大化算法,不会生成完整的注意力矩阵,极大节省了显存和计算资源。结合分块MLP结构处理,模型在计算瓶颈和显存消耗上达成了平衡,提升了推理效率和稳定性。 总结来看,gpt-oss-20b在8GB GPU上运行的核心优势体现在无量化策略基础上的FP16或BF16半精度计算,既保证了模型性能,又兼顾了计算精度。
这种做法避免了量化带来的精度损失,同时通过结合闪存以及异地缓存技术,突破了显存瓶颈。 除了技术本身,生态系统的完善也为开发者提供了极大便利。基于Python的轻量级推理库oLLM建立在Huggingface Transformers和PyTorch之上,支持多种模型及多达10万的上下文处理,能够兼容NVIDIA、AMD和Apple Silicon平台。其配置灵活,用户可以通过简单的环境搭建和安装命令快速开始,并支持加速插件如kvikio与flash-attn,进一步提升性能。 oLLM项目提供了丰富的示例脚本,涵盖文本、图像和音频多模态应用,并支持通过PEFT适配器无缝加载定制化模型,满足不同场景下的需求。无论是分析法律合同、医学文献,还是处理海量日志文件,亦或挖掘历史对话数据的常见问题,均能轻松应对。
不可忽视的是,运行gpt-oss-20b时对显存和存储容量的需求表格显示其在8GB Nvidia 3060 Ti显卡下典型显存占用约为7.3GB,配合15GB SSD存储缓存,能够保证模型的流畅运行和长文本的上下文支持。相比传统推理几十甚至百余GB显存要求,该方案极大降低了门槛。 针对技术爱好者和开发者,本文还推荐了创建虚拟环境以隔离依赖、安装oLLM及相关加速包的方法,进一步优化推理体验。此外,官方文档和社区活跃,提供详尽的故障排查方案及后续优化路线图,帮助用户持续提升模型效率。 未来,随着Qwen3-Next量化版本及视觉语言模型等新功能逐步完善,oLLM生态将愈发丰富多样,期待为多样化硬件平台和复杂应用场景带来更强支持。 综上所述,在8GB显存GPU上高效运行gpt-oss-20b,不仅是硬件与软件协同优化的成功体现,更标志着大型语言模型普及进入了新的阶段。
无论是科研人员、开发者,还是企业用户,都可以借助这种技术突破,实现更低成本、更高效的AI语言服务。未来大型模型推理将不再是高端设备的专利,更多人将享受到人工智能带来的便利与创新。 。