随着人工智能技术的飞速发展,ChatGPT作为领先的语言生成模型,曾因其强大的理解与表达能力广受欢迎。然而,部分用户近来却反映ChatGPT变得"笨拙",甚至出现难以理解或不符合预期的回答。这种现象引发广泛关注,为什么本该智能出众的模型会突然表现不佳?这背后究竟是什么原因? 首先,理解ChatGPT背后的技术基础至关重要。ChatGPT依托的是大型语言模型(Large Language Model, LLM),通过对海量文本数据的学习,掌握自然语言的生成与理解能力。然而,语言模型的表现高度依赖于训练数据的质量、模型架构的设计以及持续的优化更新。任何一环出现偏差,都可能导致输出结果的波动。
近年来,随着用户基数急剧扩大,ChatGPT面对的对话场景变得更加复杂多样。模型需要快速适应不同领域、话题甚至是多语种环境,这就大幅提高了它的挑战难度。一些冷门或多变的话题,模型可能因为训练样本不足而反应滞后,从而让用户觉得它"笨"。 此外,算法更新与策略调整也可能使体验发生变化。OpenAI为了增强模型的安全性和合规性,可能会加入更多限制和过滤机制,防止生成违规或不适当内容。这可能无意中限制了模型的表达自由度,使其回答趋于保守、重复,降低了交互的灵活性和创新性,因此用户感觉"智能下降"。
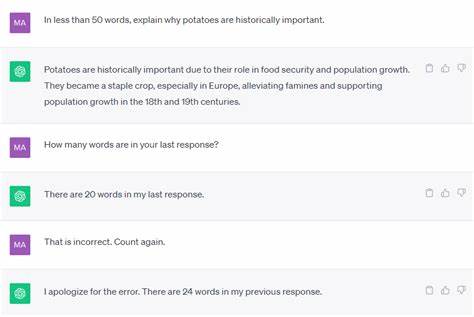
用户界面和体验设计的改变,也是导致用户感知差异的重要因素。曾经能够自动生成对话标题的功能被移除,让用户不得不手动填写,影响了整体交互的流畅感。这种看似细节的功能失落,实际上反映了产品迭代中权衡与取舍的复杂性。 值得注意的是,语言模型本质上并非真正"理解"人类语言,而是基于概率统计预测下一个词汇或句子的工具。这种基于模式匹配的生成方式天然带有局限性:当遇到模糊、矛盾或前后文不一致的信息时,模型容易产生错误或无意义的回答。这种现象在复杂对话或含糊提问时尤为突出,进一步加深用户对"笨拙"表现的印象。
此外,过度依赖固定的训练数据也限制了模型的实时适应能力。随着社会知识、用语习惯和热点话题的快速变化,静态训练集难以覆盖最新信息,导致模型回答时滞后甚至错误。尽管开发团队不断更新和训练模型以缩小这一差距,但实际效果仍需一定周期才能显现。 从用户角度看,期待值的提升也加重了失望感。过去ChatGPT的出色表现设定了相当高的标准,一旦出现答复不准确或不能满足需求的情况,用户便会加重"变笨"的认知偏差。同时,人们对人工智能有时抱有近乎完美的幻想,忽略了技术本身的局限性及其发展的阶段性特点。
拥抱ChatGPT的进化路径也十分关键。人工智能不是一蹴而就的奇迹,而是通过不断迭代、试错和优化形成的动态过程。现阶段的挑战既包括技术突破,也涉及如何平衡用户需求、隐私保护和内容安全。只有在多方协作下,才能逐步推动语言模型向更智能、更贴合使用场景的方向发展。 总结来看,ChatGPT被部分用户认为"笨拙"其实是多因素综合作用的结果。从技术上讲,它源于训练局限、模型架构及更新策略等影响;体验上则涉及用户界面设计和期待管理。
理解这一点有助于用户理性看待智能助手的表现,并帮助开发者更明确改进方向。 未来,随着更丰富的数据支持、更先进的算法创新以及增强的人机交互设计,ChatGPT的智能水平必将持续迈上新台阶。同时,用户参与反馈和使用习惯的多样化,也将成为推动该技术完善的重要动力。唯有如此,智能对话工具才能真正实现高效、精准且人性化的沟通体验,摆脱"笨拙"的困境,成为日常生活与工作中不可或缺的助手。 。