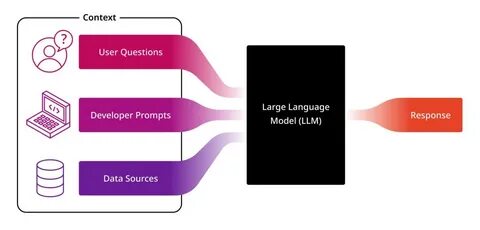
近年来,人工智能技术的迅速发展催生了以大型语言模型(LLM)为核心的智能工具,如ChatGPT、Claude和Gemini等。这些工具在职场中被广泛应用于文本生成、代码辅助、数据分析等多种场景,显著提高了工作效率。然而,面对海量敏感数据的处理,尤其是在金融、医疗等对隐私标准要求极高的行业,使用LLM引发了众多隐私与安全的担忧。本文将围绕职场中使用LLM的隐私风险、安全管理实践以及相应的法律合规问题展开探讨,力图为数据保护专业人士、决策者及一般用户提供全面深入的参考。 首先,认识LLM背后的数据隐私挑战是理解其应用的关键。大型语言模型通常通过训练海量文本数据形成复杂的语言理解和生成能力,这些训练数据往往包含大量公开与非公开信息。
若用户在使用云端LLM服务时输入包含个人身份信息(PII)、商业机密或代码等敏感内容,模型提供商可能会收集、存储甚至再利用这些信息,增加数据泄露或滥用风险。许多业内专家指出,尽管部分平台宣称对用户数据进行加密和隔离,但实际操作中数据之“隐形流动”难以完全避免,隐私泄漏隐患依然存在。 其次,职场中如何平衡LLM助力生产力与数据保护成为难点。部分从业者提出“绝不将机密信息输入任一公有云基础的语言模型”的底线策略,转而倾向本地化部署或采用隐私保护型LLM版本。例如,有企业通过内部服务器运行私有模型,避免数据离开企业网络环境,从而强化数据控制权和合规性。同时,容器化技术和虚拟机隔离被用来限制模型对其他系统资源的访问,提高操作安全性。
另一方面,也有用户因本地算力限制,依然选择公共模型服务,这时最大的挑战是设定合理的使用范围,杜绝机密数据泄露。 讨论LLM时代的版权合规问题也不容忽视。部分程序员反映,训练数据集包含自己的开源代码而未获得授权,导致在代码生成场景下权利模糊。此外,职场使用LLM辅助写作和代码编写时,必须警惕生成内容的合法性和出处,避免侵犯第三方版权或泄露企业核心知识产权。多方呼吁更透明、规范的训练数据使用及模型输出监管,推动版权保护机制配套发展。 法规层面,全球范围内针对数据保护的法规日益严格,尤其是欧盟《通用数据保护条例》(GDPR)所体现的个人数据管控精神,为LLM应用指明了合规方向。
LLM服务提供者需明确告知数据收集目的、范围及用户权利,并实现数据最小化收集和安全处理。企业在引入LLM时同样需开展详尽的风险评估,制定数据处理政策,确保符合相关法律要求并满足行业合规标准。 不少隐私专家对“AI即服务”公司的信任程度持谨慎态度,认为部分厂商宣称的“隐私保护”更多为市场营销策略而非技术保障。他们建议,企业用户寻求尽可能“可控”的解决方案,优先采用可本地部署和可审计的技术模型。此举不仅降低数据外泄风险,也便于事故发生时追责和恢复操作。 用户个人层面,隐私意识亟需提升。
多数建议是永远不要将任何不愿公开的信息输入到任何云服务的LLM中。将LLM视作公开搜索引擎的延伸,使用时仅查询非敏感的公开资料,是避免隐私风险的根本方法。同时,职场培训需涵盖AI工具的安全使用规范,使员工理解数据安全的迫切性与操作边界。 从长远看,隐私保护与LLM技术革新之间需建立良性互动。更多开源和标准化的隐私保护技术(如联邦学习、差分隐私)正在探索中,有望缓解数据集中带来的安全隐患。企业和开发者需密切关注这些前沿技术动态,结合自身实际情况科学规划LLM落地路径,兼顾生产效益与数据防线。
总结来说,LLM的职场应用带来前所未有的效率提升潜力,但也不可忽视其引发的数据隐私和版权风险。理性的态度应是既不盲目排斥,也不能放松警惕。通过选择可信赖的技术架构、执行严格的隐私合规方案,强化员工安全意识,企业方能最大化地发挥LLM优势,同时守护用户和商业数据的安全底线。未来,随着法规日益完善和隐私保护技术成熟,LLM将在职场环境中扮演更加安全且高效的助力角色,助推数字化转型迈向新高度。