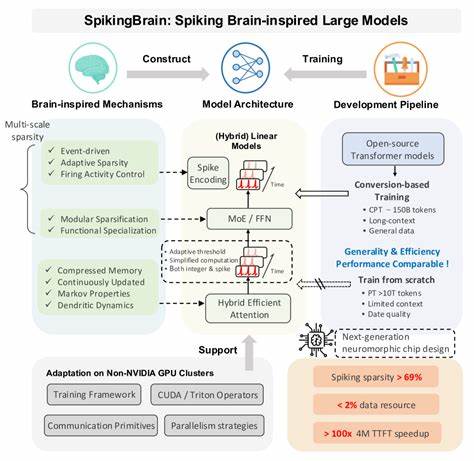
随着人工智能的迅猛发展,大规模语言模型(LLM)已成为推动自然语言处理和智能应用的重要基石。当前主流的Transformer架构虽然在多项任务中表现卓越,但其由于计算复杂度随序列长度呈二次增长,导致长上下文的训练和推理受到严重限制,尤其是在处理超长文本时效率低下、内存占用激增,成为亟待解决的技术难题。此外,主流大模型训练几乎依赖于NVIDIA GPU平台,限制了算力多样性和硬件生态的繁荣发展。针对这些挑战,SpikingBrain项目提出了一套创新的类脑大模型解决方案,融合尖端神经形态计算理念,从模型架构、算法设计与系统工程三个维度全方位提升大模型的效率和可扩展性。SpikingBrain不仅成功突破传统架构在长序列处理中的瓶颈,还实现了能耗大幅降低和推理速度显著提升,彰显了脑启发计算在人工智能领域的强大潜力。 SpikingBrain的核心特色体现在其融合了类脑神经元动态和事件驱动机制的创新模型架构。
传统Transformer基于自注意力机制,计算复杂度随序列长度平方增长,难以处理百万级甚至千万级的上下文长度。为此,SpikingBrain设计了线性及混合线性注意力结构,通过引入自适应钉扎神经元(adaptive spiking neurons),实现了对神经信息的稀疏编码和事件驱动计算,从根本上降低了时间步间冗余计算。这种非连续的激发方式启发于生物神经元的脉冲发放,显著提高了模型的稀疏性,达到超过69%的激活稀疏度,大幅降低能量消耗。此外,混合线性注意力结合专家模型(Mixture of Experts,MoE)架构,在保持模型容量扩展性的同时,实现推理内存的部分常数增长,使数千万甚至上亿长度的序列高效处理成为可能。 在模型训练层面,SpikingBrain提出了一套转换型训练管线。该管线桥接传统连续权重模型与脉冲神经网络之间的训练鸿沟,利用高效的梯度近似和差分编码技术确保训练稳定性和收敛速度。
配合专门设计的脉冲编码框架,训练过程能够充分利用稀疏事件驱动特性,减少计算冗余。这种训练策略无需庞大的预训练数据,仅用约1500亿标记token的持续训练数据,即达成了与开源Transformer基线模型相当的性能,极大地降低了训练资源消耗和时间成本。 系统工程方面,SpikingBrain聚焦于与MetaX GPU集群的深度适配,打造了定制化的训练框架和算子库,充分释放硬件潜能。通过整合多维度并行策略,诸如张量切分和流水线并行,该方案实现了训练阶段的模型规模和批处理大小的优化平衡,提高了模型FLOPs利用率。得益于MetaX的高带宽内存和定制计算单元,模型训练和推理过程达到了性能的高稳定性和可预测性,且可持续运行数周甚至数月。 SpikingBrain-7B和SpikingBrain-76B两款代表性模型是该系列的力作。
前者集成了线性注意力和自适应脉冲神经元,专注于长上下文推理效率,实测在处理400万token长度文本时,首个token生成时间提升超过100倍,突破了传统Transformer模型的限制。后者在前者基础上引入专家模型混合机制,容量达760亿参数,实现了更强大的语言建模能力和泛化性能。二者共同验证了非NVIDIA硬件平台上大规模LLM训练的可行性和稳定性,打破了行业对硬件依赖的固有观念,为异构计算和神经形态计算的融合提供了宝贵借鉴。 此外,SpikingBrain的设计哲学强调脑启发计算的能效优势,其事件驱动的激活机制意味着计算仅在脉冲触发时发生,极大地节约了能耗。结合高稀疏度激活,模型具备潜力服务于更广泛的低功耗设备和边缘计算场景,这对于未来人工智能应用的普适部署具有里程碑式的意义。展望未来,SpikingBrain团队计划进一步深化神经形态硬件的协同优化,探索更具生物真实性的神经元与网络机制,加速下一代大规模智能模型的研发进程。
总的来看,SpikingBrain创新地融合了脑科学与深度学习最前沿技术,成功突破了传统Transformer面临的效率和硬件限制,为长上下文处理和大规模模型训练开辟了新路径。其通过精巧设计的架构与算法优化,使得长序列的训练与推理实现部分常数复杂度的目标,革新了模型的性能、速度和能效表现。该项目不仅展示了脑启发计算在实际大模型应用中的巨大潜力,也推动了多样化硬件生态和可持续AI发展战略。未来随着更多研究持续融合神经科学与人工智能,SpikingBrain有望引领脑机智能计算新时代,为智能科学注入蓬勃创新动力。 。