在当前人工智能技术加速发展的时代,生成式人工智能(Generative AI)和大型语言模型(LLMs)正在迅速融入到各类应用和服务体系中,成为基础技术栈的重要组成部分。然而,随着依赖度的提高,一系列新挑战也日益凸显——包括高昂的使用成本、不可忽视的调用延迟以及API的访问限制和不稳定性。在此背景下,语义缓存作为一种创新技术方案被提出,并逐渐受到业界的关注与应用。 语义缓存的核心理念是在理解自然语言查询语义相似性的基础上,复用已有的模型回答,避免重复调用大型语言模型API,从而实现降低调用成本和提升响应速度的目标。换句话说,不同措辞表达同一问题时,通过精准判断语义上的等价性,就可以复用之前缓存的回答,大幅减少不必要的计算资源消耗。 为验证语义缓存的实际效果,Louis Cameron Booth发起了一项基于真实世界数据的实验,采用了著名问答平台Quora上公开的“问题对”数据集进行测试。
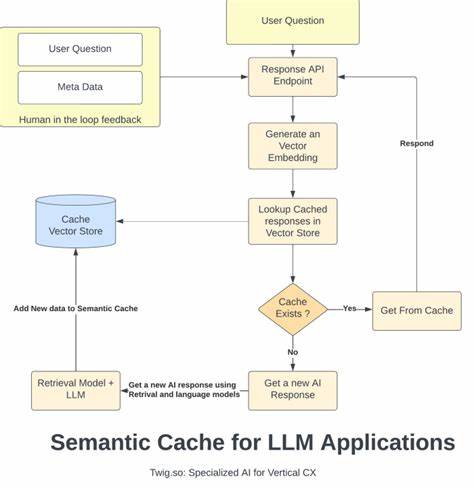
Quora数据集汇集了大量用户提出的各种问题,这些问题具有很强的人性化特点,包含拼写错误、语法不规范等真实世界表达样态。同时,Quora官方也标注了哪些问题是语义重复的,从而为语义缓存的准确性检测提供了理想的标准。 实验使用了一个名为Semcache的开源工具,作为客户端和大型语言模型API之间的缓存中间层。Semcache部署成一个HTTP代理服务器,所有对LLM的请求首先经过Semcache。其背后的技术核心是对输入查询文本进行向量化嵌入表示,通过计算此向量与缓存中已保存查询的余弦相似度,确定是否满足一定阈值(例如0.9)即视为语义命中。若命中,直接返回缓存结果;若未命中,则将请求转发到真实LLM接口获得答案,并将新问答对缓存在内存中。
实验数据规模约为2万条Quora问题,总请求数达19,400次。结果显示,语义缓存的命中率为28%,意味着超过五千个请求成功复用了缓存内容,大幅降低了对API的真实调用需求。更为显著的是,缓存命中请求的平均响应时间仅为0.010秒,而未命中请求平均处理时长高达1.648秒,提升了165倍的速度表现。 存储方面,缓存条目约为7.5KB,每条包含384维度向量嵌入、完整的回答文本及附加元数据。该设计保证缓存内存效率较高,一台拥有8GB内存的服务器理论上可保存超过一百万条问答缓存,这对于高频请求环境极具价值。 然而,语义缓存面临的核心挑战在于“语义相似性”的定义本身具有一定的主观性和细粒度差异。
Quora官方的数据标注严格分隔语义重复与非重复问题,两者之间有时存在细微语义差别。例如“Pepperoni里都有什么?”与“Pepperoni是用什么做的?”表面上看语义极为接近,但Quora并未将其归为重复;Semcache却判断为语义相似,说明模型在模糊边界上的判断可能出现误差。同理,经济学问题“弹性需求的定义”与“如何测量弹性需求”也曾被误判为等价问题,这类误判需依赖具体应用场景调整相似度阈值和选择更专业的文本嵌入模型以提高准确率。 选择合适的向量嵌入模型对系统表现影响显著。此次实验采用了通用语义理解表现优异的sentence-transformers中all-MiniLM-L6-v2模型,然而针对特定领域的问答,使用定制化或领域适配型的模型将有望进一步优化缓存的语义辨别效果,从而提高缓存命中率和准确度。 语义缓存除了在降低成本和加速响应方面展现出优势外,更包含一种战略性意义——构建专属的“知识存储层”。
这一层负责累计组织内已探索和生成的回答,独立于任何特定大型语言模型服务商。一旦第三方API遭遇不稳定或宕机,缓存系统仍然能够保障应用的持续性和用户体验稳定,大幅提升系统的鲁棒性和可用性。 部署方面,Semcache作为一个轻量级的HTTP代理不仅易于集成,还可通过云端服务进一步降低用户的维护难度,用户无需过多关注语义相似度调整、文本嵌入生成与缓存持久化等底层细节,专注于业务开发和应用创新。例如Semcache目前正在推出云托管版本,为开发者提供即开即用的语义缓存解决方案。 综合来看,语义缓存凭借其独特的技术思路和实际应用效果,在大型语言模型的实际部署中展现了极高的潜力与价值。尽管尚存在语义准确率的挑战和调优复杂度,但在节省调用成本、提升响应速度和增强系统稳定性等方面带来的好处显而易见。
随着文本嵌入技术的不断进化和计算资源成本降低,语义缓存有望成为未来人工智能应用不可或缺的重要组成部分。 对于广泛使用LLM的企业和研究机构而言,尝试引入语义缓存技术不仅能够显著优化整体性能,还能为长远的数据积累和知识管理奠定坚实基础。借助如Quora问题对这样丰富且真实的人类语义数据集进行实验验证,也为实现更加智能和高效的自然语言处理系统提供了宝贵的参考和启示。 想要深入体验语义缓存的优势,可以访问Semcache官方GitHub页面下载开源项目进行实验。同时,云端版本的测试也正在招募用户参与,帮助更多开发者轻松享受语义缓存带来的运营和技术提升。未来,随着更多创新工具和服务的落地,语义缓存将在大型语言模型的商业化及普及进程中发挥越来越重要的作用。
。