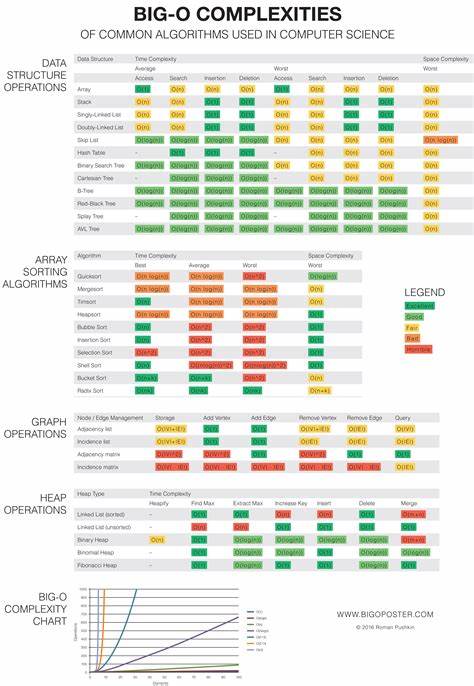
随着生成式人工智能的发展,越来越多的人开始体验由大语言模型(LLM)驱动的工具所带来的便利与挑战。从创作文本、编写代码到辅助决策,人工智能正在改变人们对生产力和创造力的认识。然而,在"再来一条提示"背后,隐藏着复杂的技术原理、伦理考量以及产品实际应用中的痛点。 生成式人工智能的核心是在海量数据基础上构建预测下一词或下一标记的模型。基于Transformer架构,这类模型通过自注意力机制实现对序列信息的理解和生成,这意味着它们更像是一种强大的统计机器而非真正"思考"的实体。这种机制的优势在于能够高效处理复杂的文本生成任务,但也导致所谓的"幻觉"问题,即模型可能会生成不准确或无根据的信息。
用户体验告诉我们,大语言模型虽然可以在短期内提升工作效率,但实际效果却远未达到期望的水平。例如,在软件开发领域的研究显示,使用AI辅助编码工具的程序员往往花费更多时间完成任务,尽管主观感受认为效率有所提升。这种错位反映了人工智能工具在实际应用中的复杂性,需要用户不仅具备基本技能,还要懂得如何有效地"提示"模型从而最大化其价值。 技术的进步正在逼近现有方法的天花板。尽管模型规模不断扩大,算法不断优化,但大语言模型无法实现真正的推理和长时间记忆,导致在上下文超长或复杂任务中表现不佳。当前对于扩展上下文窗口长度的试验虽然取得了一定进展,但信息质量的非线性下降限制了实用性。
这使得"提示工程"成为使用这类模型的必要技能,本质上仍回到了传统编程中的"指令设计"。 数据隐私及版权问题也日益凸显。很多AI开发者通过用户交互数据不断改进模型,但这引发用户个人信息被滥用的担忧。部分公司变更数据保存及利用政策,使得用户必须主动选择退出,且往往难以真正理解其后果。版权归属问题更是复杂,大语言模型生成的内容基于未明确授权的海量数据,法律界对于其产物版权归属的判定仍未达成统一。 自动化代理(Agents)被视为解决大语言模型单纯生成式缺陷的潜在方式。
通过多层模型协作和任务管理,代理旨在让AI更好地完成复杂操作和决策流程。然而,这种方法并非万能。代理执行代码时仍然存在风险,且需要大量人工监督和反馈来不断纠正错误。现实中,依赖代理完成任务依旧需要人为介入和检查,安全性和稳定性仍是瓶颈。 从软件工程角度而言,人们看到AI赋能的工具快速原型和绿地项目创造价值,但在成熟项目中其不确定性和维护成本高昂。喜欢稳定和广泛使用的技术堆栈已成为许多开发者的首选,他们更加倾向于通过传统方法保持代码质量和可维护性。
这一切提示我们,当代生成式AI仍处于"游戏"的阶段,而非完全成熟的"产品"。用户和开发者需保持理性认识,对AI的认知既不应被神话,也不可完全否定。背后的训练机制、模型局限、隐私及法律问题等均值得持续关注。 未来人工智能的发展可能会沿着更符合人类认知的路径前行,增加模型的推理能力和多模态理解能力。同时,安全性和伦理框架的构建必不可少。或许在某一天,AI能真正成为可靠的助手,而不仅是"再来一条提示"的神奇答复者。
正如某些研究指出,提升生成式AI表现需大量带注释的训练样本,这彰显了人工智能研究的复杂性和资源密集性。我们对AI的依赖和期待,需要与其内在技术现实保持一致。 综上所述,生成式人工智能虽带来了前所未有的便利和想象空间,却也不可避免地遭遇了技术瓶颈与伦理难题。理解它的内在工作机制、合理设置使用预期、关注隐私与安全,将成为驾驭这场技术变革的关键所在。人们需要在兴奋与冷静之间找到平衡,才能真正让人工智能成为促进生产力的正向力量。 。