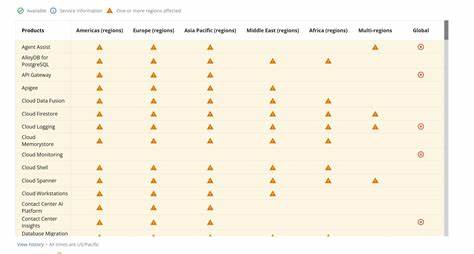
2025年6月12日,全球范围内的Google云平台(GCP)用户经历了一次罕见的大规模服务中断事件,涉及众多核心产品和服务。此次中断不仅影响了Google云多个区域的正常API请求处理和用户界面访问,也波及了谷歌的Google Workspace和安全运营产品,给数以百万计的企业用户和最终客户带来不同程度的服务体验障碍。本文将从事件的起因、具体影响、恢复过程、以及谷歌后续的改进措施等多个维度展开全面剖析,旨在帮助云计算行业用户和关注者深入理解此类大型云服务故障的复杂性与危机应对机制,并为未来选择云服务提供参考。 当日的服务中断始于上午10点51分(美西时间),当时谷歌的API管理与控制系统集群中的一个关键组件——“Service Control”遭遇了异常崩溃。Service Control作为谷歌API生态的中枢,负责处理每一个API请求的鉴权、配额检查以及策略执行,是确保API请求有效性和安全性的关键节点。这次事件的根本原因是一项在5月29日引入的新功能更新,专为增强配额策略的校验而设计。
遗憾的是,该代码路径此前从未被完全触发过,且缺少相应的错误处理机制与功能开关保护,导致在实际运行中遇到带有空字段的配额策略数据时,二进制进程发生空指针异常,陷入崩溃循环。特别是在6月12日上午10点45分,谷歌在其区域性Spanner数据库中插入的一项自动政策变更带来了含有未预期空字段的数据,这一变更在全球范围内迅速复制,使所有区域的Service Control服务遭受破坏,导致批量API请求出现503服务器错误。此次崩溃不仅瞬间影响了API访问,更波及了依赖这些底层管理层服务的诸多产品和服务,涵盖了从身份访问管理、云数据库、人工智能预测、到数据分析、云存储、及云功能等几乎所有主流Google云产品。尤其在规模较大的us-central1区域,Service Control进程的重启引发了对基础资源Spanner数据库的“群集效应”式访问冲击,在缺乏合理的指数回退机制下造成了数据库的资源过载,这使得该区域的恢复过程延长至近三小时的高风险调度,同时为了缓解压力,工程师们不得不采取限流和流量重路由操作,将部分请求转接到多区域数据库。事件爆发后,谷歌的站点可靠性工程(SRE)团队迅速介入调查,约2分钟内开始响应处理,10分钟内锁定了根因,25分钟后开启了紧急关闭该异常功能路径的“红色按钮”快速恢复机制,40分钟完成全球范围内部署。随着修复生效,大部分服务区域除了规模最大且资源瓶颈突出的us-central1外,API请求恢复正常。
接下来的数小时里,谷歌持续监控系统健康状态,清理缓存和排队任务,处理部分产品出现的后续性能滞后及错误回滚。此次事故给客户带来的影响是广泛且深远的,尤其是依赖低延迟和高可用API的业务系统,API请求的大量503错误不仅直接阻断业务流程,也导致监控系统报警产生误判,一些用户甚至无法通过Cloud Service Health获取准确事件信息。谷歌对此深表歉意,公开承认此次事故不仅损害了客户业务连续性,更冲击了用户对谷歌云平台稳定性的信心。为避免类似事件再次发生,谷歌已经制定并开始实施多项技术及管理改进。首先,将对Service Control架构进行模块化重构,使关键功能之间实现隔离并默认“开放失败”模式,即在部分校验失败时仍尽量保证API请求通畅。其次,加强全球复制的数据发布策略,确保元数据变更有充分验证及分步推送过程,防范无效数据瞬时扩散。
再增设功能开关与错误防护,以便新功能上线可控逐步激活,避免未充分测试的功能导致系统崩溃。此外,还将强化系统自动化测试和静态代码分析,完善异常状态下的系统降级措施,确保遭遇未知错误时优雅失败而非全面宕机。同样,谷歌将升级SRE团队的响应工具与事故通报流程,提升客户通知速度与透明度,保证即使在监控及Cloud Service Health系统受影响的情况下,也能及时提供准确无误的服务状态信息。此次事件还揭示了云服务行业面对全球分布式系统复杂性与实时一致性挑战时的脆弱点。谷歌作为行业领导者,其痛苦经验成为所有云计算提供商的重要参考与警示。事件发生后,行业专家呼吁更为完善的灰度发布、场景测试以及多层次容灾设计,确保关键通路的弹性与自治能力。
对用户而言,面对云服务商的偶发性故障,增强自身系统的弹性设计同样关键。建议企业用户建立跨区域备份策略、异地多活架构和合理的故障切换方案,及时关注云厂商的服务公告及状态页,合理评估服务中断风险对业务的潜在影响。利用API限流、重试机制和超时设置等客户端防护手段减少单点故障对业务流程的冲击,也成为现代云时代应用架构的必修课。展望未来,谷歌云将在不断探索与创新中,致力于提升平台服务稳定与用户体验。同时,本次事件的深刻教训将驱动行业迈向更高水平的安全合规、可靠性和透明度。无论是企业客户还是技术从业者,都应从中获得启示,合理部署并运营云资源,构筑更加稳健的数字化基础。
总结来看,2025年6月12日Google云平台多产品大范围服务中断事件,彰显了全球云计算基础架构在复杂环境中面临的挑战,以及跨国科技巨头应对危机时的敏捷反应与责任承诺。它既是一场痛苦的故障,更是推动业界技术进步与服务革新的重要契机。随着谷歌发布完整的事故分析报告和持续优化,云端世界的韧性和智能必将进一步提升,为数字经济的可持续发展奠定坚实根基。