随着人工智能、大数据和科学计算等领域的快速发展,GPU加速技术因其在并行计算能力上的显著优势,成为提升计算性能的重要手段。然而,在许多实际应用环境中,尤其是云端或普通服务器配置中,常常面临只有CPU而无GPU的限制。如何在纯CPU环境中运行GPU加速代码,已成为业界关注的热点话题。远程GPU内核执行技术应运而生,突破了传统硬件边界,实现了计算资源的跨设备协同,极大扩展了GPU计算的适用范围。远程GPU内核执行,是指在本地无GPU的系统环境中,将GPU相关的计算任务通过网络发送到远程拥有GPU资源的服务器或集群上,远程执行GPU内核程序,完成计算后将结果返回,令本地应用体验到GPU加速的性能优势。此方法不仅有效解决了硬件受限问题,还充分利用分布式资源,实现计算能力的动态调配。
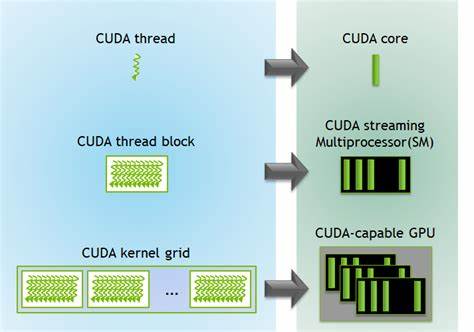
该技术的实现依赖于高效的通信协议、数据传输机制以及GPU内核代码的异构适配。首先,通信协议必须具备低延迟和高吞吐量特点,确保远程调用时延最小化。主流方案多采用基于RDMA(远程直接内存访问)或高性能网络协议构建的消息传递系统,优化数据的传输路径,并应用压缩或增量更新等手段减少带宽占用。其次,数据在CPU和GPU之间的移动通常是性能瓶颈,远程执行要求对内存管理和数据布局实现细粒度控制,减少重复传输和不必要的数据拷贝。通过智能缓存策略和预加载技术,可以进一步提升远程调用的响应速度和稳定性。此外,为了兼容不同硬件架构及驱动版本,GPU内核代码一般采用开放标准如OpenCL或跨平台框架CUDA的远程执行接口进行封装,保证代码的可移植性及调试便利性。
远程GPU内核执行技术在实际应用中展现出巨大的潜力。诸如大型科学模拟、机器学习模型训练和渲染计算等场景,较为依赖GPU加速,而部署成本及硬件环境限制常成为瓶颈。通过远程执行,用户无需改动既有CPU环境,便可调用云端或数据中心的GPU资源,既节省资本开支也避免资源浪费。此外,远程GPU执行还可促进计算资源的共享和负载均衡。多用户多任务环境下,通过统一调度平台合理分配GPU资源,提高整体效率和硬件利用率,满足多样化且动态的计算需求。然而,远程GPU内核执行同样面临诸多挑战。
网络波动及延迟可能导致性能不稳定,数据安全和隐私也需严格防护策略支撑。开发者需构建健壮的错误恢复机制和加密传输协议,确保计算过程的可靠和可信。未来,随着5G及下一代高速网络普及,网络瓶颈将有所缓解,远程GPU计算的普适性和灵活性进一步增强。同时,人工智能驱动的智能调度算法将优化任务分配,实现自动化、高效的异构计算环境。此外,边缘计算与云端GPU资源的深度融合,将促使该技术在智能制造、自动驾驶及医疗影像等领域发挥关键作用。综上,远程GPU内核执行技术为解决CPU环境下GPU加速需求提供了创新方案,打破了计算资源的物理限制,在提升计算性能的同时推动计算架构与服务模式的转型。
未来,随着技术成熟和相关生态完善,这一方式有望成为加速计算的新常态,赋能更多行业迈向智能化与高性能的新时代。 。