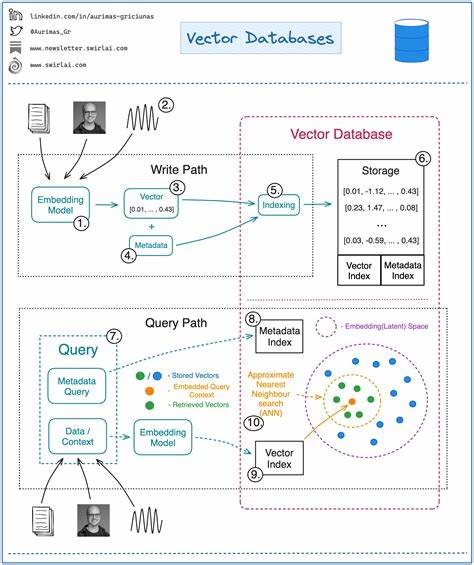
随着人工智能和大数据技术的迅猛发展,向量数据库作为支持高效相似性搜索和机器学习模型训练的重要基础设施,受到了越来越多的关注。尤其是在图像识别、自然语言处理和推荐系统等领域,向量数据库承担着海量数据存储与快速检索的双重任务。然而,传统向量数据库在大规模数据处理时面临诸多挑战,严重制约了其实际应用效果。模式感知向量数据库(Pattern Aware Vector Database)作为一种创新技术,通过对数据内部结构和模式的深刻理解,实现了对传统向量数据库的突破性改进。本文将深入剖析模式感知向量数据库的原理,探讨现有向量数据库在规模化应用中失败的原因,并展望未来向量数据库的发展方向。 向量数据库最显著的功能是其高效的相似度搜索能力。
当数据以高维向量形式存在时,快速准确地检索与查询向量最接近的记录成为核心需求。传统向量数据库通常采用基于索引结构如倒排索引、树形结构或者近似最近邻算法实现相似性搜索,尽管在中小规模数据中表现尚可,但当数据量达到亿级以上时,即面临维度灾难、索引构建成本高昂、搜索效率下降以及存储开销急剧增加等问题。其关键瓶颈在于缺乏对数据分布和内部模式的感知,导致索引和检索过程失之粗糙,无法适应海量高维数据的复杂性。 模式感知向量数据库则引入了一种全新的数据处理方法。它不仅将向量视作单一的数值点,而是深入挖掘向量背后的潜在结构和规律,通过模型识别数据在高维空间中的聚类、趋势和分布模式,形成更具智能化的索引体系。例如,算法会动态调整索引策略,根据局部数据密度选择不同的近邻搜索技术,甚至将向量拆解成更具语义解释力的子模式表示,从而大幅提升搜索的准确性和响应速度。
此外,模式感知数据库还能自适应地优化数据压缩和存储方案,缓解了存储资源的压力,确保在海量数据场景下的系统稳定运行。 现有的向量数据库在规模化应用失败的根本原因主要可归结为三个方面。第一是索引结构的单一与静态性。传统索引缺乏灵活性,难以针对不同数据分布动态调整检索策略,导致查询时面临较大延迟。第二是数据维度诅咒带来的性能瓶颈。随着维数增多,向量空间变得稀疏,简单的距离度量失去有效性,原有的近似检索算法表现下降明显。
第三是缺乏对语义和结构信息的深度利用,使得检索结果的相关性受限,难以满足用户多样化的查询需求。模式感知向量数据库通过引入机器学习与深度学习技术,挖掘数据间复杂的模式关联,提供了突破传统瓶颈的解决方案。 在实际应用中,模式感知向量数据库展现出卓越的性能优势。以电商推荐系统为例,平台通过模式感知数据库能够更精准地捕捉用户行为中的微妙变化,实现对用户兴趣的实时理解和高效匹配。再如在智能医疗领域,通过分析患者历史数据的内在模式,系统快速定位相似病例,加速诊断和治疗方案的制定。模式感知技术使向量数据库不仅仅是被动的数据存储工具,更成为智能数据处理和知识发现的核心引擎。
未来,随着数据规模的进一步扩张和应用场景的日益多样化,模式感知向量数据库将继续融合更多前沿技术。边缘计算和联邦学习的结合,将赋予数据库更强的分布式处理能力和隐私保护机制;自监督学习技术的引入,将帮助数据库自动发现更深层次的模式,提升无监督环境下的检索效果。同时,标准化建设和开放生态的形成,将促进模式感知向量数据库的行业普及和创新迭代。总结而言,模式感知向量数据库以其对数据内部规律的深刻認知,成功破解了传统向量数据库在大规模应用中的瓶颈,开启了数据存储与检索的新纪元。随着技术的不断进步和应用的不断深入,模式感知向量数据库必将在人工智能、大数据等领域发挥更加重要的作用,推动数字经济迈向更加智能和高效的未来。